
What Is Network Redundancy & What Technologies Ensure It
One critical concept in computer networks that network supervisors and IT teams should pay particular attention to is the error tolerance threshold.
This concept means continuing the work of a communication infrastructure after a problem or failure. Redundancy is the solution to overcome this problem.
When communication systems and networks are implemented based on the redundancy principle, a component’s failure does not cause network disruption, as the equipment can continue working.
That’s why large organizations and companies design networks based on redundancy and error tolerance principles.
Redundancy of power supplies
Hard drives are prone to malfunction because they have rotating magnetic plates. However, disks are not the only component that may fail in a system. The power supply may also fail. For this reason, it is recommended that plans be built with a dual power supply so that in case of a power supply failure, the second power supply enters the circuit, and the system will continue to operate.
On newer servers, errors related to the central processor can also be detected, and the motherboard can transfer computing and processing processes to the second central processor.
Also, memory errors are predictable and manageable, so information is not lost during memory failure. Combining these factors makes it possible for a communication network to operate without problems and send a warning to the network administrator by observing the slightest sign of failure, without disrupting business performance.
If the power supply fails in one of the network’s most important equipment, such as the server, the server will stop functioning first, and then the network will stop functioning. If you have the best support contract, you must wait at least 4 hours for the new power supply to arrive, and the server will continue to operate.
Therefore, when designing networks, you should pay special attention to the principle of high accessibility.
Fortunately, you can purchase most network equipment with an optional second power supply. Dual power supplies work in a variety of ways, with the following three being the most popular:
Active/Passive Dual Power Supplies
In this method, power supplies are divided into primary and secondary states. The direct power supply is activated, and the second power supply is in inactive or, more precisely, standby mode.
In this case, only one power supply can provide the Power the server needs.
- One potential problem of active-inactive dual power supplies is that only one power supply works simultaneously. When the system’s power supply process encounters a problem, the second power supply enters the circuit. All the device’s workload is transferred to the dual power supply in inactive mode. If the passive power supply is dissipated over time and the workload is assigned, it will likely not function properly.
- Dual Load Balancing Power Supply: Both power supplies work in an active-active configuration. Both powers supply the electricity needed for the equipment equally, which is called the “load balancing” approach. The dual load-balancing power supply has the same problem as the active-passive dual power supply model, as both power supplies are forced to supply the electrical current required by the device.
- Dual power supply with load change: This is a widely used forum server and data center equipment. Its function is similar to that of the active and passive dual power models, except that sometimes the load is temporarily transferred to the second power supply and driven to the main power supply twice. The advantage of this method is that it is possible to test both the power supply and, therefore, problems can be identified before the system’s permanent power outage.
An array of standalone disks (RAID)
A copy must be placed on a secondary device when installing the operating system on a hard drive or Secure Digital (SD) card. Figure 1 shows the pattern above. The most common method used in this area is the additional array of independent disks (RAID-1).
This approach is also called flipping. The above pattern improves the tolerance threshold for system error in drive failure or the support card.
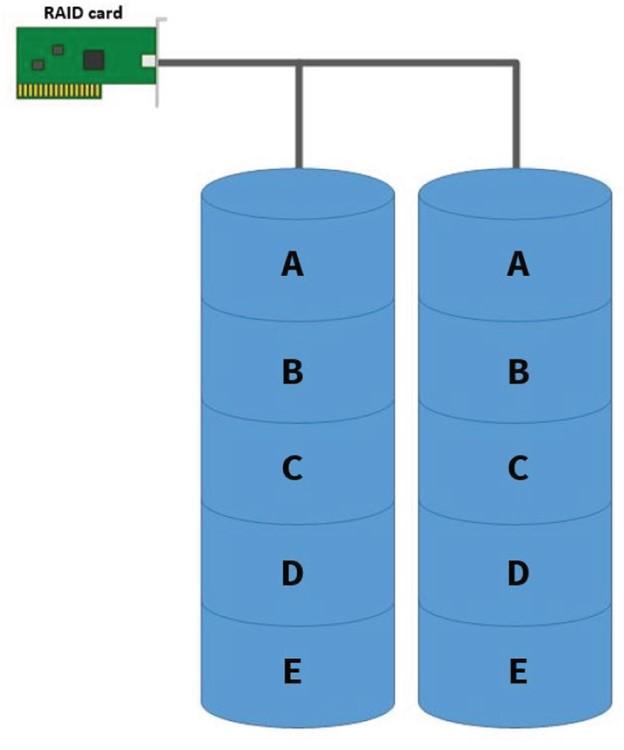
Figure 1
An important point to consider about the redundancy of storage equipment is the architecture on which hard drives are configured. For example, flip-based redundancy costs a lot of money because you must move the same volume to keep a copy of information for every purpose: host communication.
That’s why some companies use striping and RAID-5. In the above method, you need three or more drives. The above pattern is shown in Figure 2.
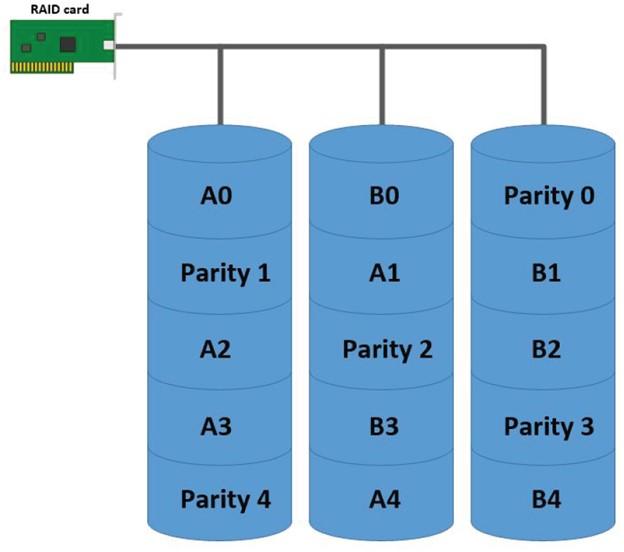
Clustering servers
Today’s servers can be purchased redundantly to keep the server functioning if parts fail. However, the vital thing to note about component redundancy is that the system’s periodic evaluation process increases, and some models lack software mechanisms that intelligently distribute heavy processing loads between different servers.
Accordingly, companies use a concept called clustering. Clustering refers to grouping servers that can balance workloads, simplify maintenance, and prevent failure and loss of a network or set of services. For example, Windows Server 2019 and 2022 offer a functional feature called Failover Clustering, which provides high app availability.
The critical thing about physical clustering is that the above approach was quite popular 5 to 10 years ago, but today, most companies use the virtual clustering approach.
In this case, if one server fails, running programs will automatically redirect to another server. However, to achieve this, the application must support the feature.
Microsoft Hyper-V, VMware vSphere, and Citrix Hypervisor (XenServer) are a few examples of popular virtual clustering software used in data centers today.
These platforms can be used as group platforms to access servers and workstations. Workstation access is usually done using virtual desktop infrastructure (VDI).
In this case, programs can be placed in containers on these platforms using Docker or Kubernetes. The above approach significantly reduces application costs (because companies do not need expensive licenses). A program similar to a virtual machine is made available to the user. Figure 3 shows an example of virtual clustering.
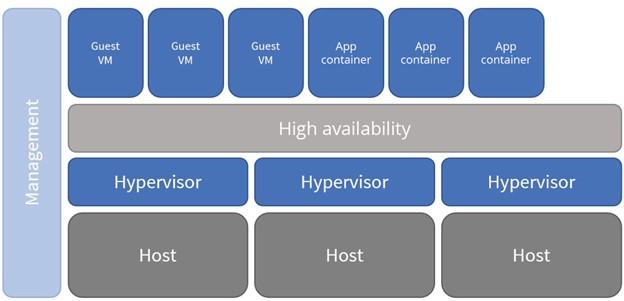
Figure 3
Typically, each host is similar to others in clusters, has its own hypervisor, and can access shared resources such as bandwidth, storage space, and processing power. Most virtual solution providers allow users to download their hypervisor and use it for free, as each host and its hypervisor operate independently of others.
However, when hosts work together simultaneously, they form a cluster, and the service that connects these hosts ensures high availability. A high accessibility feature is a criterion that provides virtual solutions with many advertising maneuvers.
Switches
Until this part of the article, we saw how to achieve the principle of high availability in computing and storage space. However, another essential thing to note is that there may be a definite problem and disability in the links between switches that are responsible for linking hosts and switches. So, we must consider solving this problem to preserve the principle of high accessibility.
Therefore, we need to look for a solution to achieve redundancy of network connections so that a link between the equipment is not interrupted in case of failure.
An important point to consider about switches is the Spanning Tree Protocol (STP), which blocks additional link frames so that broadcast storms and duplicate boundaries are not a problem.
However, if a link breaks down, STP will repeat the calculation process and allow the frames to be moved via an additional link, which will cause a tangible drop in network performance.
As shown in Figure 4, bypassing all network switches by creating redundancy on the web is possible. Sometimes, the distribution of the main layer may crash and send information incompletely.
Usually, buying additional buttons for these layers is costly, and if the daily business set is heavy, the problems should be resolved quickly. In such circumstances, redundancy ensures that business activities will continue in the event of failure.

Figure 4
Routers
If the router fails due to a repair or failure, it will no longer respond to requests and routing packets via the virtual IP address. To achieve the redundancy principle associated with routers, we must look at FHRP first-hop redundancy protocols, HSRP Hot Standby Router Protocol, and VRRP Virtual Router Redundancy Protocol.
These protocols allow you to configure an accessible default gateway by providing a synchronized virtual router; Figure 5 shows how to achieve redundancy associated with routers.
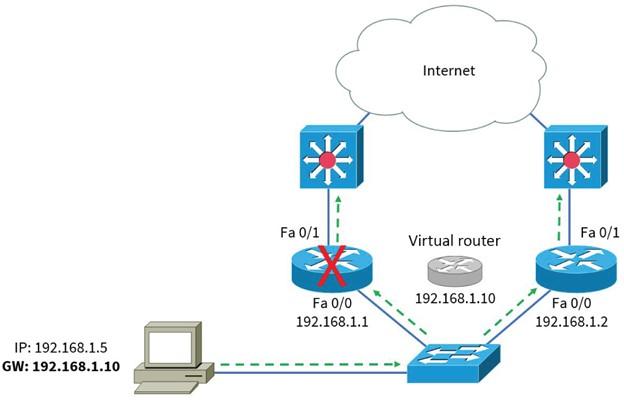
Figure 5
Firewalls
Firewalls are another network component that should be considered for high accessibility. In this context, routers can use the standard FHRP protocols. Figure 6 shows how to implement redundancy associated with firewalls.
Suppose you are using FHRP to achieve an additional firewall that is supposed to connect to the Internet. In that case, you should consider the critical point that the service provider supports this approach. We can use FHRP for outbound traffic redundancy, but the provider should also help FHRP with incoming traffic redundancy.
It isn’t easy to achieve such an objective if an organization uses two different providers. Also, both firewalls must have the same configuration to prevent potential security problems on the network.
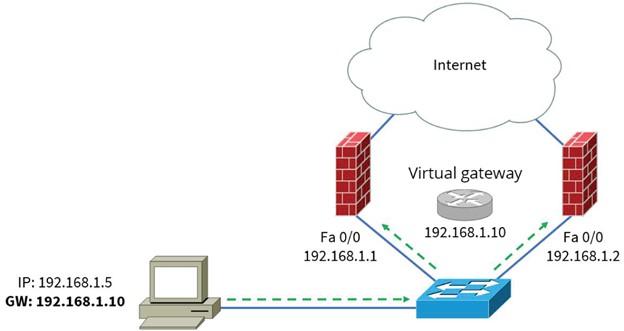
Figure 6
Support, facilities, and infrastructure
When buying network equipment, you must research supporting equipment and infrastructure comprehensively. This concept is called Ping and Power and revolves around network management and remote device control.
Ping and Power has a general approach and includes various equipment such as air conditioning systems (HVAC), humidity measurement, equipment performance, power outages, and fire extinguishing.
Power outages are the most critical threat to networks, but proper maintenance of HVAC equipment and fire prevention are essential issues that should not be ignored.
Uninterrupted Power Supply (UPS)
An uninterrupted power supply (UPS) is an emergency power support system that detects any fluctuations in electricity flow while providing electricity and automatically supplies the required electricity whenever urban electricity is cut off.
The subtle thing to pay attention to about UPS is that you need to activate a UPS only for a limited time and provide the energy required for the equipment as soon as the generator is in operation as a constant source of electricity.
In connection with workstations and servers that are not connected to backup generators for any reason, UPS gives you enough time to shut down systems. UPSs are often mistakenly used as a source of energy during power outages. Regular UPS can supply equipment for a minimal period and is not suitable for long-term outages.
The advantage of using UPS and generators simultaneously is that the equipment will not fluctuate when the generator is commissioned after the power outage.
So, in connection with the redundancy principle, be careful that upscale systems should provide electricity only as long as a power generator is set up. Today, there are many types of UPS systems, three of which perform better:
Standby UPS
The most common places under a desk are available to protect your computer. These UPSs work by transferring load from the AC line to the battery inverter, and capacitors in the load transfer unit help the system avoid severe power fluctuations. Due to their limited capacity, these models perform well but are not used in server rooms.
Linear Interactive UPS
They are commonly used for small server rooms and racks. Their performance is based on the electricity supply from the AC line to the inverter. When a power outage occurs, the inverter receives a signal to generate electricity from batteries. This process may sound similar to the performance of a standby UPS, but in this model, no-load handling is done.
The load must be changed from AC to a completely different circuit (inverter) in standby mode. In contrast, the inverter is always connected to the pack in a linear interactive UPS, but it only works with the battery during power outages.
Online UPS
The standard option is data centers. This model supplies AC power to the rectifier/charging circuit that keeps batteries charged. The batteries then supply inverter energy with a fixed DC power supply. The inverter converts DC into AC twice to provide the required electricity.
The advantage of online UPS is that electricity is constantly supplied from batteries. The fixed-load power supply unit enters the circuit during a power outage and offers a fully stable power supply.
FAQ
What is redundancy in networking?
Redundancy in networking refers to adding backup devices, links, or systems to ensure continuous operation and minimize downtime if the main network components fail.
Which equipment is commonly used for network redundancy?
Equipment such as backup routers, switches, firewalls, and duplicate power supplies are often used to provide redundancy in a network.
What technologies can help achieve network redundancy?
Technologies like load balancing, failover clustering, RAID storage, and virtualization are commonly implemented to ensure high availability and fault tolerance.