












What Efficient Tools Are Available For Big Data Analysis?
Today, All Companies Active In The Supply Of Business, Large Or Small, Are Immersed In The World Of Information And Data, Because They Are Constantly Producing Different Types Of Information.
Big Data Analysis, That valuable information may be published on the company’s website or social media. Information that sometimes takes hours to view.
The further we go, the greater the amount of information produced. In this case, it is essential to find and analyze the correct data and get the right results from them.
The term big data refers to a large amount of data and its processing. Every large organization and business can process data using advanced tools in this field and get excellent results. Today there are various tools in collecting, processing, and viewing big data.
In addition to practical tools, the frameworks and methods available to professionals for this purpose should be mentioned. The most important is Apache Hadoop, MapReduce algorithm, Hadoop Distributed File System.
Apache Hive, Apache Mahout, Apache Spark, Dryad, Storm, Apache Drill, Jaspersoft, and Splunk.
Data processing professionals typically use batch processing, stream processing, and interactive analysis to analyze the data regardless of their tools. Most batch processing tools are based on the Apache Hadoop infrastructure and the Apache Mahout and Admiral.
Streaming data processing programs are primarily used for real-time analysis. The essential infrastructure related to this group should be Storm and Splank.
Interactive analysis allows professionals to interact directly and in real-time with data and process them instantly. For example, the Dremel and Apache Drill are the main infrastructures of this group, which provide good support for interactive analysis.
Each of these tools is used for specific applications, and it is not the case that a single instrument is used to process any large data set. Accordingly, this article introduces the tools for big data processing developers.
Apache Hadoop and the reduction mapping approach
Hadoop is an open-source software framework used to process distributed extensive data hosted on clusters of servers. The framework is written in Java and is designed for processing distributed on thousands of machines with high error tolerance.
One of the main reasons professionals use Hadoop for big data analytics is the lack of dependence on expensive hardware because of the infrastructure of fault tolerance in clusters and software algorithms to detect and manage failures at different layers. This infrastructure is widely used by large companies such as Meta and Google and supports RPC communication technology called Remote Procedure Call.
Apache Hadoop includes Hadoop kernel, reduction mapping algorithm, Hadoop distributed file system, and Apache Hive.

Reduction mapping is a programming framework for big data processing based on a partition and solution approach.
The division and solution method is implemented in two steps: Map and Reduce.
Typically, Hadoop manages the data processing process based on the pattern of the primary node and the working node. The central node divides the input into two smaller subproblems and distributes them to the functional nodes in the mapping step. The central node then combines the outputs for all sub-problems in the reduction step.
This framework is helpful for fault-tolerant storage and the processing of large volumes of data. Due to the excellent performance of this mechanism in big data processing and a powerful instrument for considerable data processing pace, Hadoop is the leading infrastructure used in this field. The core of Hadoop is made up of a storage component called the Hadoop Distributed File System and Processing / Mapping.
Hadoop breaks the files into large blocks and distributes them among the nodes of a cluster. For data processing, the Map / Reduce section sends code to the nodes so that the processing can be done in parallel.
In the above model, the processing is first performed on available local nodes to process data faster.
The main Hadoop framework consists of modules of the Hadoop Commons section (including libraries and software packages required), the Hadoop HDFS distributed file system (a distributed file system that stores data on cluster machines and optimally uses bandwidth), and YARN ( A resource management platform is responsible for managing computational resources in clusters) and Map / Reduce (a programming model for large-scale data processing).
Hadoop prepares a distributed file system that can store data on thousands of servers, distribute executable tasks on machines, and perform data processing through a reduction mapping mechanism.
As mentioned, Hadoop is based on the MapReduce pattern, which represents a large distributed compute as a sequence of operations distributed over a set of key/value pairs. The framework selects a cluster of machines and applies the user-defined reduction mapping process to the groups in that cluster.
In this process, two mappings and a reduction of calculations are performed based on a data set of key/value pairs.
In the mapping step of the framework, the input data is divided into many pieces, and each piece is assigned to a mapping task. Each mapping task uses the given key/value pair and generates a middle key/value pair. Therefore, the many mapping tasks also manage the distribution process between cluster nodes.
For each key/value pair (Key, Value), the mapping step calls a user-defined mapping function that converts the input to a different key/value pair. The next phase of the framework mapping sorts the middle data according to the key and generates a set of pairs (K, V) to display all the specific fundamental values together. In addition, it divides the set of multiples into several parts equal to the number of reduction tasks.
Each work process receives a multiple (K, V) in the reduction step and processes them. For each multiplier, each subtraction task calls a user-defined subtraction function that converts the multiplier to a key/value pair output (K, V). After performing the required processing, all the processes performed on the cluster nodes are distributed, and the appropriate intermediate data piece is transferred to each reduction task.
Tasks at each step are executed legally against error so that if a node fails in the calculation process, the assigned reading will be redistributed to the remaining nodes. High mapping and reduction tasks result in good load distribution and allow unsuccessful charges to be re-performed with low overhead.
Map / Reduce architecture.
Hadoop Map / Reduce framework is based on architecture (Master / enslaved person). This framework has a Controller server called job tracker and Save servers called task tracker per node in the cluster. Job tracker is the point of interaction between users and the framework. Specialists send redundancy mapping tasks to the job tracker to place them in a queue of pending charges and execute them based on the first-entry / first-service approach. Job tracker manages the assignment of mapping and reduction tasks to task trackers. Tasktrackers accomplish tasks based on the job tracker instructions and manage the data transfer process between the mapping and reduction steps.
1. HDFS Hadoop beating heart
The Hadoop Distributed File System is a secure solution for storing large files on clusters. HDFS stores each file as a sequence of blocks. It should note that all the files’ blocks are the same size except the last block. All information is duplicated (reproduction). All information is copied (replication) to overcome the error problem and increase the system’s tolerance. Of course, you can adjust the block size and copy factor in each file.
The HDFS structure consists of a name node, a controller server that manages the file system namespace and allows clients to access files. In addition, HDFS files support the Write Once a feature, meaning that only one user can manipulate them at a time. HDFS uses the Master / Slave approach and the reduction mapping framework.
In addition, there are several data nodes. Data nodes enable access to operations such as opening, closing, renaming files and folders via the RPC protocol. In addition, the data node is responsible for handling read and write requests received from filesystem clients. It should say that generating, deleting, and making copies of blocks is done according to the instructions of the data node.
2. Apache Mahout
The second platform in this area is Apache Mahout, which provides a robust infrastructure for big data processing, scalable machine learning methods, and data analysis software. The main Mahout algorithms include clustering, categorization, pattern exploration, regression, dimensionality, evolutionary algorithms, and batch participatory filtering based on Hadoop infrastructure.
Apache Mahout also uses a redundancy mapping framework for data processing. Major companies that use Apache Mahout and scalable machine learning algorithms include Google, IBM, Amazon, Yahoo, and Facebook.
3. Apache Spark
Apache Spark provides another macro-processing framework that is open source and is used for fast processing and complex analysis. This framework, which is of interest to Iranian developers, was built in 2009 at the UC Berkeley AMPLab laboratory. Spark allows developers to write their applications in Java, Scala, or Python. In addition to the reduction mapping algorithm, Spark supports social dialogs, data streams, machine learning, and graph data processing.
Spark has several components, the most important of which are the driver program, the cluster manager, and the worker nodes. The cluster manager manages the resource allocation process to process the data as tasks. The framework is also based on the Hadoop Distributed File System (HDFS) infrastructure, except that it has changed the core infrastructure to make some things faster and better done.
Each program contains a set of processes called executables. The most significant advantage that Apache Spark has over similar models is that it supports the deployment of Spark applications in the Hadoop cluster. Figure 1 shows the Apache Spark architecture.
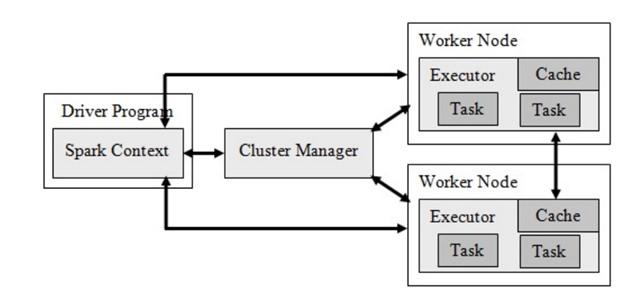
figure 1
Spark’s primary focus is on the Resilient Distributed Datasets, which stores data in memory and have good usability capabilities to deal with crashes. In addition, it supports recursive computing and provides high-speed data processing. In addition to reducing data streams, Spark also supports machine learning and graph algorithms. Another significant advantage of Spark is Java, AR, Python, and Scala programming languages.
Spark architecture is such that it can execute a program in the Hadoop cluster a hundred times faster because it fetches data into memory and performs all processing activities in memory. For this reason, a lot of main memory is needed to use the above framework. Spark is written in the Scala programming language and runs on a Java virtual machine.
4. Storm
The Storm is a distributed real-time computing system with error tolerance for processing data streams. This infrastructure, unlike Hadoop, is designed for batch processing intended for real-time processing. In addition, it is simple to set up and implement.
Developers consider the Storm for two crucial reasons: scalability and fault tolerance. Developers can implement various topologies on the Storm directly opposite the Hadoop infrastructure, which uses a reduction mapping algorithm to execute the corresponding applications.
Storm consists of two types of primary and worker node clusters. The controller and worker nodes create two maps, nimbus, identical to the reduction map’s job tracker and task tracker components. Nimbus is responsible for distributing code in the Storm cluster, scheduling and assigning tasks to worker nodes, and overseeing the entire system.
5. Apache Drill
Apache Drill is another distributed system for interactive data set analysis. The drill uses the Hadoop Distributed File System (HDFS) for storage and reduction mapping for batch analysis. The infrastructure has more flexibility to support colloquial languages, data formats, and data sources. In addition, the system is capable of supporting nested data and can support up to 10,000 servers. More precisely, it is capable of processing data at the petabyte scale.
6. (Dryad)
Admiration is a significant programming paradigm for implementing parallel and distributed programs for managing data flow graphs. This paradigm includes a cluster of computer nodes and allows the developer to use the resources of a collection to execute programs in a distributed manner. The main advantage of the above paradigm is that the user does not need to know the technical details of concurrent programming.
A navigation program is executed on a computationally-oriented graph consisting of computational vertices and communication channels. Because of this, Admiral can offer a wide range of capabilities such as graphing work, scheduling machines for existing processes, transition failure handling in clusters, and visualizing the outcome.
7. (Jaspersoft)
Jaspersoft’s open-source software package is attractive to developers because it generates reports on database columns. This package provides an expandable metadata analysis infrastructure and can quickly visualize data on popular storage platforms such as MongoDB, Cassandra, Redis, and the like. One of the essential features of Jaspersoft is that it processes, converts, loads, and processes big data quickly and easily.
In addition, it can build interactive reports and dashboards based on HTML directly from the data warehouse. The information generated by this infrastructure is shared with different people.
8. Splunk
Splank is a real-time, intelligent infrastructure for processing the big data generated by intelligent machines and sensors. The platform combines super-centric technologies and various processing algorithms so that developers do not have a particular problem searching, monitoring, and analyzing machine-generated data through a web interface. Splank delivers results to developers in innovative ways such as graphs, reports, and alerts.
Splunk’s differences with other tools include indexing structured and unstructured data generated by machines, real-time-search, analytics results reporting, and dashboards. This infrastructure has been developed to provide benchmarks for various applications, error detection for IT infrastructure, and intelligent support for business operations.
last word
The evidence clearly shows that the volume of data collected from various fields and industries worldwide will be at least twice as much as now in the next two years. Usually, this data is of no use unless analyzed for helpful information. It necessitates the development of methods to facilitate macro data analysis. It converts data to knowledge with high-performance, high-scalability processes. And it is a complex process that is expected to be reduced by using parallel and distributed processing in emerging computer architectures.
You need to pay attention to two critical points about data and big data. The first is that data always has the problem of uncertainty, and the second is that they often have missing values. Such issues negatively affect computational models and systems’ performance, impact, and scalability.
It is necessary to conduct applied research on big data and record and effectively access data. In addition, programming metadata analysis is another problem in this area. Explaining data access requirements in applications and abstract programming language design to exploit parallel processing are other requirements in this area.