What Is The Field Of Data Engineering And Why Did It Emerge?
Our Personal And Digital Lives Are Enclosed In The Realm Of Data That Is Constantly Being Generated.
Therefore, it is not surprising that a field called data engineering has become one of the critical trends in the world of information technology; it is almost one of the most profitable jobs that experts familiar with artificial intelligence and data can achieve.
A field that directly focuses on data transfer, conversion, and storage. In recent years, businesses have generated massive amounts of data. They need a data engineer who can collect, organize, store, and transform data into a format that makes big data analyzable. This strategy plays a vital role in increasing the income level of companies.
The semantics of data engineering should be searched in its engineering section. In the same way that engineers are responsible for design and construction, data engineers also design processes and lines of data transmission so that data can be stored, transformed, and transmitted So that the information reaches data scientists in an optimal way and without problems and can be used. Today, data is obtained from various sources and stored in a data warehouse to access information through a reliable data source.
One of the essential differences is that data engineering, with other jobs in the IT field, is hidden in its dynamism. Because the nature of information is constantly changing, the job description and the list of required skills of a data engineer are variable. Therefore, data engineers must continually think about learning new skills.
Engineering that engineers data
A data engineer is an information technology specialist whose main task is to collect data for analytical or operational applications. While collecting data, these software engineers are responsible for building data transmission lines to collect data from different sources. They integrate, organize, and clean data for analytical applications. More precisely, they structure the data. Accordingly, data engineers are attracted to organizations with the aim of easy access to data and optimization of the extensive data ecosystem.
The amount of data an engineer works with depends on the field of work and the size or smallness of an organization. The larger the organization, the more complex the analytical architecture is, and the engineer is responsible for handling a larger volume of data. Specific industries, such as healthcare, retail, and financial services, are among the sectors that generate the highest volume of data. A data engineer attracted to such ambitions takes on a lot of responsibility and should be paid more.
Data engineering refers to skills and expertise that clarify data analysis to help businesses make reliable business decisions.
The role of a data engineer
Data engineers focus on collecting and preparing data to be used by data scientists and analysts. Typically, data engineers are recruited by organizations in the following three ways:
- General Mode: Data engineers work in small teams, and their goal is to collect, receive, and process data. They may be more skilled than some data scientists but less knowledgeable than systems architects.
- Project mode: A data engineer may enter into a contract with a company to collect data related to sales or how users use that company’s services and prepare it for analysis. In addition, he may be responsible for building dashboards that simplify data access and provide predictions about future events by analyzing existing data.
- Data transmission line engineers: These data engineers, in the form of a team of specialists, are responsible for the collection and transformation of data in medium projects and the task of implementing distributed systems in more complex projects. Typically, medium and large companies seek to hire this model of data engineers.
For example, a regional food delivery company may need a data pipeline project to make data scientists and analysts easily accessible to food delivery-related metadata. The company may want to know how far and how long it took to deliver food last month.
Then, use this data in a predictive algorithm to determine what strategy he can maintain and expand his business activities.
- Database-centric engineers: These data engineers implement, maintain, and populate analytical databases. This role usually exists in large companies whose data is distributed across multiple databases. Engineers interface with data pipelines at these companies, configure databases for efficient analysis, and create table schemas using extract, transform, and load (ETL) methods. It should be explained that ETL is a process in which data is copied from multiple sources to a single destination system.
The databases that are supposed to be used in data-oriented projects have a complex architecture, and their design is done specially. In addition to creating the database, the data engineer is responsible for writing code that collects data from various sources, such as application-specific databases, and sends it to the analytical database.
Why was data engineering invented?
In the last decade, almost all companies have experienced digital transformation in the sense that they are producing a massive amount of structured or unstructured data. Data has become more complex than before and is generated at high speed. Typically, data scientists can only do their jobs properly if they understand the concept of data correctly and have access to classified and refined data.
For a data scientist to be able to work with this data, an expert is needed to ensure the quality, reliability, and usability of the data so that patterns and analyses can be found.
When the concept of big data was first introduced to the world of information technology, the process of building data transmission buses was the responsibility of the data scientist, but because it was not considered one of the essential skills of data scientists, the process of data modeling was not done well.
This issue caused problems such as rework and data instability. So, companies could not use data correctly, and some data-driven projects faced failure.
The unimaginable increase of data by technologies such as the Internet of Things and the competition for data-centricity made companies need data engineers who have the necessary skills to design the infrastructure required for data projects so that data scientists can use data.
As we mentioned, the data engineer works on building the data transmission bus. In Figure 1, you can see an example of these data transmission buses. In this figure, you can see a simplified illustration of a data transfer pipeline. In this line, data is obtained from various sources and entered into the data lake. An integrated data model is created, duplicate data is removed, the combined data model is made once again, and finally, entered into the product database.
Usually, data is obtained from various sources, the most important of which are the following:
- Internet of Things tools
- Telemetry of cars
- Websites owned by retailers
- Social networks and messenger programs
- User activity in a web application
- Any instrument used for measurement
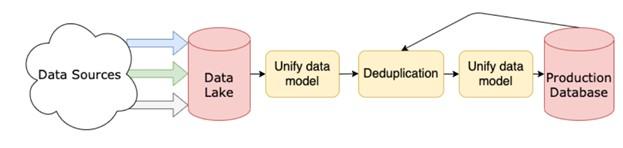
figure 1
What are the responsibilities of a data engineer?
Data engineers often work alongside data scientists as part of an analytics team. These professionals provide data in usable formats to data scientists who write dialogs and algorithms that can act on this information. In addition, data engineers are responsible for making the collected data available to managers, business analysts, and end users to analyze and make better business decisions. Algorithms are used to provide predictive analysis, and it is possible to use them in machine learning and data mining programs.
In general, the field of data engineering deals with structured and unstructured data. Structured data is information that can be organized into a structured repository, such as a database. Unstructured data such as text, images, audio, and video files do not conform to conventional data models. For this reason, professionals in this field must have a detailed understanding of data architecture and applications to manage both types of data.
What technologies and tools are data engineering mixed with?
Typically, data-driven disciplines such as data engineering are closely related to programming languages. As a result, specialists in this field must be able to work with programming languages such as C#, Java, Python, R, Ruby, Scala, and SQL. However, Python, R, and SQL are three important languages widely used by professionals in this field. In addition to programming languages, complementary tools such as ETL and REST API should not be neglected. These tools simplify access to ready-made datasets for data analysts and business users.
When data is received from various sources, it must be stored in places known as data warehouses and data lakes. For example, Hadoop was developed to process and store enterprise data warehouses and helps data engineers keep big data in a structured way.
One of the technologies that play a vital role in the field is data engineering, NoSQL databases, and Apache Spark systems, which have become big players in this field. Of course, relational database systems such as MySQL and PostgreSQL are still used in this field.
Fortunately, the Lambda architecture supports integrated data pipelines for batch and real-time processing. Today, business intelligence (BI) platforms and their configurable capabilities play an essential role in data engineering. They have almost simplified the work of data engineers in this field. Business intelligence platforms allow data engineers to connect data warehouses, lakes, and other data sources effectively. For this reason, data engineers try to learn how to work with the interactive dashboards that business intelligence platforms provide, along with practical skills.
One of the essential topics raised around data engineering is whether there is a connection between data engineering and machine learning when machine learning is one of the skills that data scientists or machine learning engineers need.
The reality is that data engineers must have a good understanding of machine learning to prepare data for machine learning platforms.
A subtle point to note about data engineering is the platform the engineers use. Typically, professional data engineers use Unix-based operating systems. They need to know how to apply machine learning algorithms and get the insights required.
Statistics show that Linux-based operating systems such as Ubuntu, Solaris, and similar examples perform better than Mac and Windows operating systems in this area. Linux distributions give the user more control over operating system monitoring, which is helpful for data engineers.
Certifications related to data engineering
Like most IT certifications, data engineering certifications are often based on a specific vendor’s products, and training and exams focus on using this software. Since the job of data engineer has become more attractive than in the past, companies like IBM have prepared specialized certifications for professionals in this field. Popular data engineer certifications include the following:
- Certified Data Professional: The Institute for Certification of Computational Professionals (ICCP) has prepared this certificate and states that a data professional has sufficient knowledge to work with public databases.
- Cloudera Certified Professional Data Engineer: This certificate shows that a person can receive, transform, store, and analyze data in data-oriented environments. Candidates can register directly to participate in this course and receive its certificate and must answer at least 70% of the questions correctly.
- Google Cloud Professional Data Engineer: This degree shows that professionals can use machine learning models, ensure data quality, build and design data processing systems, and test them. The test that Google has considered for this purpose is a two-hour multiple-choice test. There are no official prerequisites for taking this course, but Google recommends that you have experience working with the Google Cloud Platform before taking this course.
The critical thing to note is that certifications alone are not enough to get a data engineering job, and you need to have the necessary practical experience. Typically, data engineers use the following methods to gain experience:
- Relevant academic degrees: We recommend obtaining a bachelor’s degree in applied mathematics, computer science, physics, or engineering. Also, a master’s degree in computer science or engineering can set you apart from other applicants for this job.
- Online courses: Inexpensive or free online courses are an excellent way to acquire data engineering skills. Today, many educational videos are available in Persian and English, as well as many free online courses and resources. For example, Codecademy’s Learn Python teaches data engineers Python, an essential skill in the field. Coursera is another good resource for Linux server management and security. GitHub SQL Cheatsheet is a repository on GitHub that is constantly updated with sample SQL cheatsheets.
- Additionally, various publishers, such as O’Reilly, publish e-books on data engineering that cover significant data architecture and data engineering topics. Is. Finally, Udacity is one of the most comprehensive video platforms. This educational institution’s videos teach data engineering topics in the most accurate way possible. Fortunately, the films of this institution are available on Persian language sites.
- Along with these educational resources, take project-based learning and practical work seriously. A project-based approach is an excellent way to maintain motivation and learn the basics of essential topics. Hands-on projects help you understand data engineering skills in the best possible way and improve your skill level.
last word
As you can see, data engineering is an essential skill that makes data engineers and data scientists work as a team on data-driven and machine-learning projects. Data scientists can only use data to analyze and complete tasks. Data engineeringThey prepares and organize the data that companies have in databases and other formats. It defines data pipelines so that data scientists can easily access data.
However, we should not lose sight of data scientists and engineers having different job descriptions. Data engineers strive to perfect their knowledge and skills in working with other technologies; Therefore, their focus on improving their skill level is not limited to one specific skill. In contrast, data scientists often focus on specialized areas. They must analyze the data accurately.