
Who Is A Deep Learning Engineer And What Skills Should He / She Have?
Deep Learning Is One Of The Most Important Branches Of Machine Learning, Which Tries To Use A Method Similar To The Human Mind To Perform Calculations.
In-depth learning involves complex scientific concepts and algorithms and is mainly used to solve complex real-world problems.
Deep learning is a multi-layered (cell-based) algorithmic machine learning method inspired by the human brain’s neural network.
The term deep refers to the number of layers through which processed data is transferred to another layer.
By Using in-depth learning, machines can teach machines what humans do. Today, deep understanding is one of the essential skills that large companies and organizations need to solve complex problems.
Therefore, it is not surprising that professionals receive large salaries.
From a job and employment perspective, there are two critical roles in the world of deep learning:
the Deep Learning Researcher and the Applied Deep Learning Engineer.
The first group needs mathematics-based science to do their job to properly understand the concepts of deep learning and then develop new technologies and algorithms.
The second group focuses on working with technologies, algorithms, and patterns that result from the first group of researchers to produce products that meet the needs of the industry eventually.
Today, companies in artificial intelligence and deep learning organize teams in different ways and use other terms to describe their tasks that are similar but not the same. What confuses some people is that some concepts and skills in artificial intelligence, such as data engineering and modeling, have similarities, but they are not precisely the same.
The critical question that arises is the job description of each job or what skills are hired?
Analytics interviews 100 data science and machine learning experts for an accurate answer.
After gathering all the information, the technical jobs in this field were divided into six main categories, each requiring its skills. This article will examine the skills required of an in-depth learning engineer based on data from the analytics website.
An AI project is based on a five-step program. These five steps are so extensive and detailed that no specialist has enough time and skill to complete all five steps alone. Team members have different skills, each focusing on a specific cycle part.
In Figure 1, you can see the six job titles that play an essential role in these five steps, along with their job descriptions. To prepare an AI team, you need skills to complete the five-step life cycle of AI projects.
Typically, the artificial intelligence development teams, from the beginning, focus on data engineering and modeling, as they must validate the possibility of realizing an idea or implementing a project.
As the project enters the development phase, the team focuses on how to deploy and analyze business needs and the AI infrastructure.
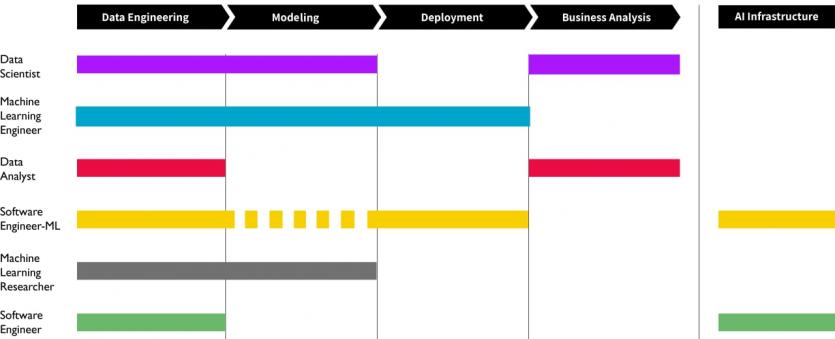
figure 1
What is the job description of a deep learning engineer?
The deep learning engineer is responsible for data engineering, modeling, and deploying work processes. The most important tasks of this person should be mentioned as follows:
- Data-related tasks: Defining data requirements, collecting, labeling, inspecting, clearing, adding, and transferring data.
- Tasks related to modeling: teaching deep learning models, defining assessment standards, searching for meta-parameters, and applying research to provide new solutions.
- Deployment-related tasks: Convert prototype code to executable code, prepare the cloud environment to apply the model, optimize response times and maintain bandwidth.
What skills does a deep learning engineer need?
Deep learning engineers need skills that combine engineering, business, and science (Figure 2). While deep-learning engineers focus on coding prototypes and product codes, data scientists focus primarily on coding prototypes, and software engineers focus on writing product code.
In contrast to the job descriptions of machine learning engineers, deep learning engineers need to have sufficient knowledge about other topics as well. For example, a deep learning engineer may work on applications based on deep learning, such as speech recognition, natural language processing, and computer vision.
For this reason, they should be familiar with different neural network architectures (fully connected networks, convolutional neural networks, recursive neural networks, and similar examples).
Suppose you want to test your level of proficiency in the job title of Deep Learning Engineer. In that case, we suggest the standardized tests of machine learning, deep learning, data science, mathematics, algorithmic coding, and software engineering at https://workera.ai/product. Do the / workers-test / insert.
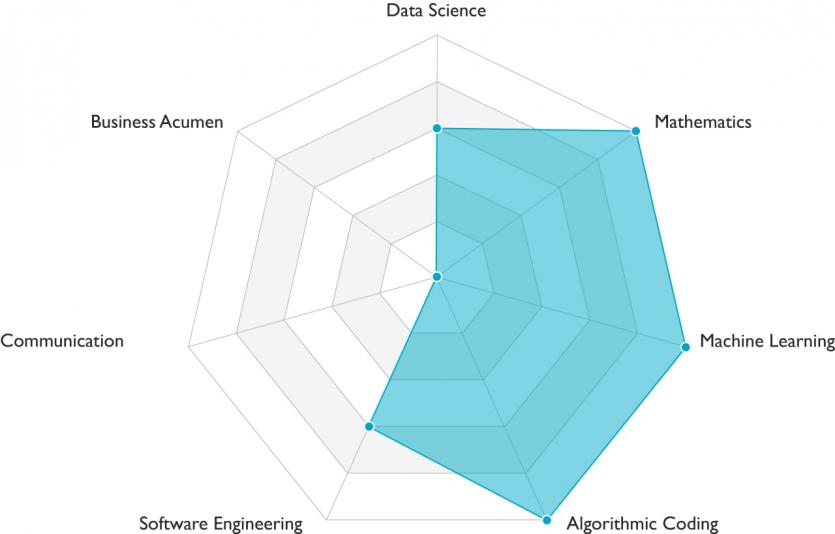
figure 2
What topics should a deep learning engineer have sufficient knowledge of it?
In general, the job descriptions of deep learning engineers in different companies are almost the same. For this reason, a deep learning engineer must have sufficient knowledge of the following skills:
R or Python, suitable for deep learning and machine learning [ML1]
Common languages used for deep learning are Python and R. Both languages have their characteristics, and it is not the case that if you learn one of them, you should leave out the other. When you start learning one of them, you have to know all the technical details and syntax of them to use them to code intelligent algorithms without any problems.
Try to focus as much as possible on learning libraries related to your field of work to use them in real projects without any problems. Fortunately, there is no particular problem in learning these languages; choose a reliable and well-known source and spend a few hours a day learning the language of your choice.
Basics of computer science and data structure
Familiarity with how machine learning and deep learning algorithms alone is not enough, and in practice, you should know the knowledge and skills of a software engineer about concepts such as data structure, software development life cycle, gateway, and algorithms (sorting, searching, and optimization).
When working on a project in the real world, the customer is reluctant to know the technical details of the performance of a model, and it is important to him what services the program or service provides. Therefore, the design should be as structured as possible and away from complexity.
Many data science enthusiasts think that to work in artificial intelligence and deep learning, they must have sufficient knowledge of a small number of algorithms and then learn one or more libraries and applications. In other words, they are reluctant to focus on learning specific data structure concepts. Whereas when working on a project, you must have the correct data structure for the application to be efficient in memory and execution speed.
Mathematics in the world of artificial intelligence
If you are a software engineer, you do not have a problem converting ideas into software code. Still, you need to have enough knowledge of mathematics and statistical concepts for machine learning. It helps to analyze each algorithmic model and Set the basis for what you need.
Unfortunately, some believe that most of the required algorithms have already been written and tested, so when using them, it is enough to make a few small changes to them to be usable in different areas.
This view is wrong. Statistics refers to the process of analyzing a set of data that is used to determine the unique mathematical properties of that data. Mathematics is the mainstay of all AI jobs and even programming. To analyze the outputs, use variance (standard deviation), milestones, and more; you need to have sufficient knowledge of statistical and mathematical topics.
Mastering the probability subject helps better understand the different artificial intelligence models and machine learning. Machine learning starts deep from statistical operations and then moves on. The criteria used to describe the data set are mean, median, exponent, variance, and standard deviation.
Deployment services and application technologies in the field of front end and user interface
Once you have designed, implemented, and developed a model, you now need to show it to others in charts or visual representations. People do not have the technical knowledge to understand complex issues and may not even know how algorithms work. Be; Therefore, you need to describe the operation and what the algorithm does in simple terms.
In addition, the factor that can increase the popularity of the algorithm is an attractive user interface to show what products you have produced. Thus, familiarity with libraries and frameworks such as Django, Flex, and even JavaScript can help you create an engaging, user-centric interface. Once everything is ready, you should use technologies like Apache and Wamp to complete your task.
If you are part of a large team, there are many specialized developers in the field of background and front, but if you are a member of a small group, you will probably have to do both front and back development yourself; It’s hard work, but sometimes you have to go beyond your scope.
Necessary knowledge related to cloud computing
The volume of data is getting bigger and bigger day by day, and therefore it can not manage on a local server. That’s why we need to move towards cloud technologies.
These platforms offer a wide range of application services, from primary data to infrastructure for model development. Some of these platforms also provide solutions based on deep learning.
The most popular of these are Azure, Google Cloud, and AWS. These are the technologies that it is recommended that you think about learning. Getting acquainted (gain, obtain) with present-day techniques from Cloud Computing is a bit of a chore, but if you’re going to use cloud-based virtual machines, you need to learn the basics. But if you are interested in learning more, be sure to work on cloud computing as an in-depth learning engineer.
What tool does the deep learning engineer use?
Deep learning engineers use different tools in different companies, but some are more prominent. The most widely used tools in this field are the following:
- Deep learning engineers typically use Python for modeling. Numpy, Scikit-Learn, Matplotlib, TensorFlow, and PyTorch are some libraries and frameworks you should consider learning.
- Given that the data is stored in databases, it is essential to know how to implement SQL dialogs.
- Familiarity with object-oriented programming languages (such as Python, Java, and CiplusPlus) and super-centric technologies such as AWS, GCP, and Azure are essential.
- Familiarity with version control systems such as gate and subversion is essential to advance project goals.
There are several choices available to deep learning engineers regarding project coding. However, the integrated development environment of Jupyter Notebook, Sublime, and project tracking and management tools such as JIRA is essential.
last word
The world around us is changing with the development of artificial intelligence and its sub-branches. For this reason, the need for machine learning and artificial intelligence engineers has become more acute than before.
Artificial intelligence will play an essential role in the future in many devices, from smartphones to IoT devices and self-driving cars.
The importance of this role is growing day by day, as it is estimated that over the next two years, artificial intelligence will create more than 2 million new jobs.