
What Is Text Mining, Why It Matters, and How It’s Done
Text mining, also known as text data mining or text analytics, is the process of extracting meaningful information from unstructured text data using computational techniques.
In an era defined by information, a vast portion of valuable data is not stored in structured databases but exists in the form of text. Emails, social media posts, customer reviews, news articles, and scientific papers are all examples of this unstructured data.
Manually analyzing this massive volume of text to extract meaningful insights is practically impossible. This is where text mining comes into play.
What is Text Mining?

Text mining, also known as text analytics, is the process of using automated methods to derive high-quality, relevant information and patterns from unstructured text data. In simple terms, if data mining is the science of finding patterns in large structured datasets, text mining is its equivalent for textual content.
The core idea is to transform unstructured text into a structured format that can then be analyzed to uncover trends, topics, sentiments, and relationships that would otherwise remain hidden.
Why Do We Need Text Mining?
The importance of text mining stems from the exponential growth of digital text. Organizations and individuals need it to:
- Understand Customer Voice: Businesses can analyze thousands of customer reviews, survey responses, and support tickets to quickly gauge public opinion, identify product issues, and understand customer sentiment (positive, negative, or neutral).
- Gain Competitive Intelligence: By monitoring news, websites, and social media related to competitors, companies can stay ahead of market trends and strategic shifts.
- Manage Risk and Security: Text mining is utilized in security to identify threats by analyzing communication patterns and in legal fields for e-discovery, enabling the rapid sifting through of millions of documents.
- Accelerate Research: Scientists and researchers can use text mining to scan thousands of academic papers to find relevant information and discover connections between different studies.
How is Text Mining Done?
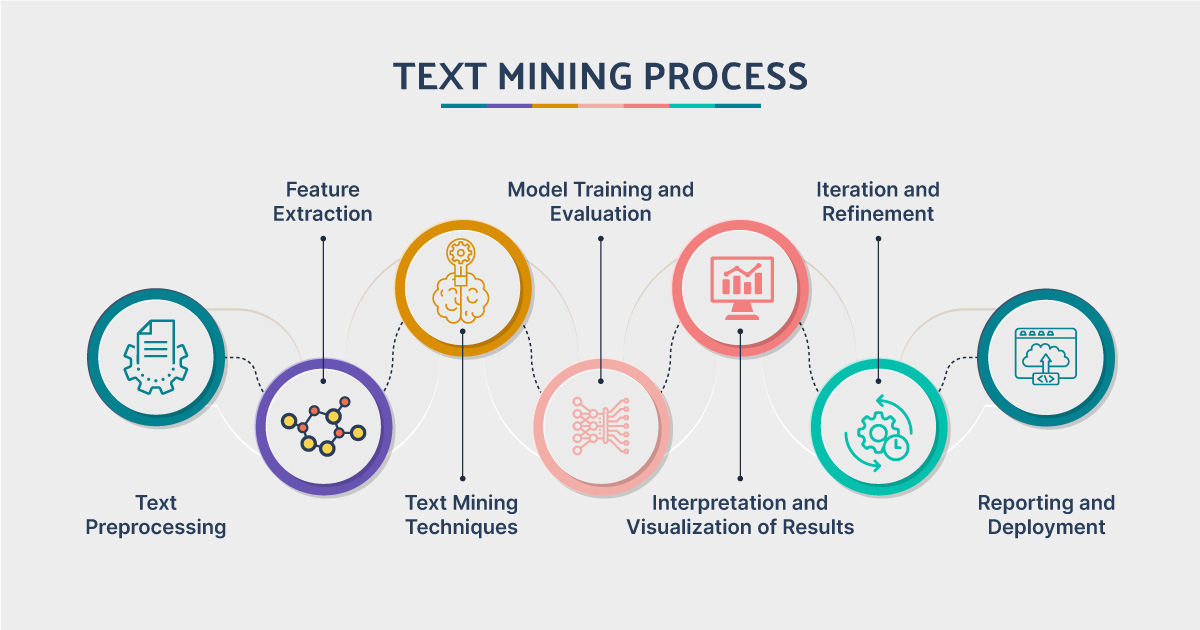
Text mining is not a single technique but a multi-step process that heavily relies on Natural Language Processing (NLP), a field of artificial intelligence that enables computers to understand and interpret human language. The typical workflow includes:
- Information Retrieval (Data Gathering): The first step is to collect the relevant text data from various sources, such as web scraping, accessing databases, or using APIs for social media platforms.
- Preprocessing: Raw text is messy. This crucial step cleans and prepares the text for analysis. Common tasks include:
- Tokenization: Breaking down the text into individual words or sentences (tokens).
- Stop-Word Removal: Eliminating common words (e.g., “the,” “is,” “a”) that carry little analytical value.
- Stemming and Lemmatization: Reducing words to their root form (e.g., “running” and “ran” both become “run”).
- Pattern Extraction and Analysis: This is the core of text mining, where algorithms are applied to the processed data to extract patterns and analyze them. Key techniques include:
- Text Classification: Assigning predefined categories to text (e.g., automatically sorting emails into “Spam” and “Inbox”).
- Sentiment Analysis: Determining the emotional tone behind a text.
- Topic Modeling: Identifying the main topics or themes within an extensive collection of documents.
- Named Entity Recognition (NER): Locating and classifying key information like names of people, organizations, and places.
- Interpretation and Visualization: The final step involves presenting the discovered patterns in a clear and understandable format, often using graphs, charts, or dashboards to help humans make informed decisions based on the results.
Technical Analysis
The article provides a solid and clear introduction to text mining, accurately framing it as a critical tool for making sense of the modern world’s deluge of unstructured data. The core value of text mining, as the article implies, is its ability to convert chaotic, human-generated text into structured, machine-readable insights, which is a cornerstone of modern business intelligence and data science.
Bridging the Gap Between Human and Machine
The most profound aspect of text mining is that it tackles the most “human” form of data: language. While traditional data analytics focuses on numbers and discrete values, text mining delves into opinions, intentions, emotions, and context.
This enables organizations to move beyond merely knowing what happened (e.g., “sales dropped 10%”) to understanding why it occurred (e.g., “social media sentiment turned negative after a recent software update”). Sentiment analysis, mentioned in the article, is perhaps the most potent commercial application of this, as it provides a real-time pulse of the market’s voice.
The Engine of AI-Powered Services
Text mining and its underlying NLP technologies are not just analytical tools; they are the engine behind many AI services we use daily. For example:
- Spam filters in email clients use text classification.
- Customer service chatbots use NER and intent recognition to understand user requests.
- Recommendation systems on e-commerce sites can analyze product reviews to suggest items.
This demonstrates that text mining is not an isolated academic discipline but a foundational technology for a wide range of practical, value-adding applications.
Challenges and the Future
While powerful, text mining faces significant challenges that drive ongoing research. Human language is inherently ambiguous. Sarcasm, irony, slang, and cultural context are particularly challenging for algorithms to interpret accurately. A review saying “Great, another feature that nobody asked for” is technically positive in its word choice, but negative in sentiment.
The future of text mining is moving towards more sophisticated deep learning models (like Transformers) that can better grasp context. The evolution is from simply extracting keywords to truly understanding meaning and even generating human-like text. This progression blurs the lines between text mining (analysis) and generative AI (creation), opening up new frontiers for automated content summarization, report generation, and hyper-personalized communication.
FAQ
What is text mining?
Text mining is the process of extracting useful information, patterns, and insights from large amounts of unstructured text data using techniques from natural language processing (NLP), machine learning, and statistics.
Why do we need text mining?
We need text mining to analyze unstructured data such as emails, reviews, social media posts, and documents, so organizations can discover trends, understand customer opinions, detect risks, and make data-driven decisions.
How is text mining done?
Text mining is typically done through steps like text preprocessing (tokenization, stop-word removal, stemming/lemmatization), feature extraction (TF-IDF, word embeddings), and applying analytical methods such as classification, clustering, sentiment analysis, or topic modeling.