
What Is Data Mining With Python? All About Data Mining With Python
Data Mining With Python: Nowadays, understanding the science of data mining and utilizing Python for data mining is crucial due to the high volume of data, and governments and organizations have recognized its importance in enhancing their efficiency.
Learning the Python programming language is currently one of the most popular skills in the world, and mastering various Python libraries is essential in most data science careers.
It can be said that it is one of the languages that are very useful in data mining science, as many people have adopted it due to its versatility and simplicity.
Additionally, this plan, gauge, with its various libraries, has led most programmers to use it. Therefore, in this article, we aim to provide a comprehensive description of data mining using Python.
It is essential to note that Python data mining training courses aim to explain all the methods and steps of Python data mining in a step-by-step manner for real-world projects.
Additionally, for those unfamiliar with Python, the language is briefly introduced, and key points for preparing for data analysis with Python are explained.

Why Data Mining with Python
To solve their complex problems in various fields, data science professionals need to be familiar with a powerful programming language.
Therefore, the Python language has been able to achieve a good position among experts in this field due to its extensive and up-to-date libraries in the field of data science. Why the implementation of data mining with Python has been considered:
- The simplicity of Python
- There are numerous libraries available in Python.
- The widespread use of the Python programming language in the field of data mining
- Ability to implement and use it in a variety of operating systems
Benefits of Data Mining with Python
Among the benefits of data mining are the following:
- Importing different types of data in various formats is considered one of the advantages of data mining with Python.
- The ability to process large volumes of data is a key advantage of data mining with Python.
- One of the advantages of data mining with Python is the ability to perform both simple and advanced statistical analysis.
- Data preprocessing is a key advantage of data mining with Python.
- Another advantage of data mining with Python is the ability to visualize data.
- Another advantage of data mining with Python is the implementation of machine learning algorithms.
- Confusion matrix and model evaluation are other advantages of data mining with Python.

Who are the participants in the data mining course with Python?
Participants in the Python data mining course are graduates with master’s and doctoral degrees in nuclear engineering, industry, artificial intelligence, computer software, automation, and Information technology management, spanning various fields such as program project management.
Writing, data mining, web programming, banking systems design and analysis, business process management, and scheduling.
Who is the Python data mining course suitable for?
- People who want to get acquainted with one of the most critical data mining tools in a short period, and analyze their customers’ data.
- The Python data mining course is also suitable for sales managers and marketers who want to analyze their customer data.
- Experts who work in the field of customer relationship management and intend to learn methods of analyzing customer data.
- Students and graduates who intend to use data mining science as part of their preparation to find a job in the field of customer relationship management and data mining.

Required libraries
As we mentioned earlier, to perform data mining operations with Python, we need to become familiar with the libraries required for Python data mining, so that we can utilize them to execute code. Among the libraries required for data mining with Python are the following:
Numpy Library
This library is widely used in scientific calculations within the Python programming language. The library provides tools for integrating C, C++, and Fortran code, and is also used in Fourier transform calculations, linear algebra, and generating random numbers.
The NumPy library provides programmers with predefined functions for performing numeric operations.

Scipy Library
It is an open-source library used in mathematics, engineering, and science. The SciPy library modules are applied in various fields, including optimization, integration, statistics, linear algebra, and Fourier series, as well as differential equations. Using this library, n-dimensional arrays can be accessed and manipulated.
Matplotlib Library
It is one of the two-dimensional libraries used to draw diagrams in Python. This library enables programmers to convert their data into graphs quickly.
This library can also be used for simple scripts. Other uses for this library include web server applications, graphical user interfaces, and Python programming. This library primarily focuses on popular machine learning algorithms.
Pandas Library
This library enables users to provide Information with a high-level structure for simple operations and data analysis.
Gensim Library
This library is utilized in thematic modeling, document indexing, and the retrieval of similarities within large documents.
It is noteworthy that to use libraries in data mining with Python, they must be called before Coding as follows:
1 2 3 4 5 | <span style=“font-size: 16px;”>import pandas as pd import matplotlib.pyplot as plt import numpy as np import scipy.stats as stats import seaborn as sns</span> |
The steps for implementing data mining with Python are as follows:
Step 1: Prepare the data
The first step in implementing data mining with Python is to prepare the data for analysis. There are various ways to utilize different libraries, depending on the type of data and the desired outcome. Data preparation for popular machine learning algorithms is one of the most critical data mining tools with Python, which has the following applications:
- Analyze data
- Manage incomplete data
- Data normalization
- Categorize data into different types
- Introduce data to the program through the Command
For example, the data from a work sample, comprising 50 samples from three flower models, is evaluated. The received data has five rows, the first four rows are the values,s, and the last row is the sample class, and the order is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 | <span style=“font-size: 16px;”>import urllib2 url = ‘http://aima.cs.berkeley.edu/data/iris.csv’ u = urllib2.urlopen(url) localFile = open(‘iris.csv’, ‘w’) localFile.write(u.read()) numpy import genfromtxt, zeros # read the first four columns data = genfromtxt(‘iris.csv’,delimiter=‘,’,usecols=(0,1,2,3)) # read the fifth column target = genfromtxt(‘iris.csv’,delimiter=‘,’,usecols=(4),dtype=str) print set(target) # build a collection of unique elements set([‘setosa’, ‘versicolor’, ‘virginica’])</span> |
Step 2: Data Imaging
To understand what Information the data provides and how it is structured, it is an essential aspect of data mining that this Information can be obtained with the help of illustrations and graphics.
Using graphs helps us to compare the values of two different datasets graphically. Therefore, one of the steps in implementing data mining with Python is data visualization. For example, by writing the following Command, a Graph is drawn:
1 2 3 4 5 | <span style=“font-size: 16px;”>import plot, show plot(data[target== ‘setosa’,0],data[target ==‘setosa’,2],‘bo’) plot(data[target== ‘versicolor’,0],data[target ==‘versicolor’,2],‘ro’) plot(data[target== ‘virginica’,0],data[target ==‘virginica’,2],‘go’) show()</span> |
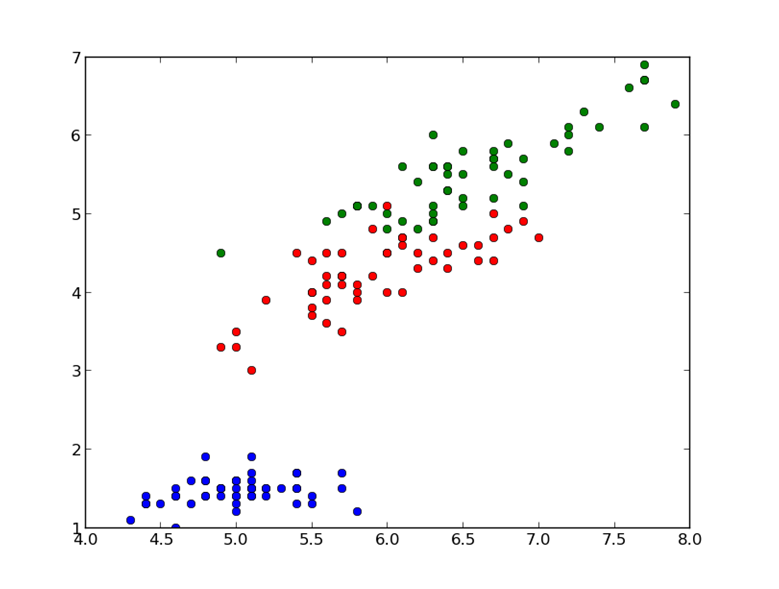
The Graph above contains 150 dots, each represented by three colors, which correspond to the classes.
Step 3: Classification and Regression
Understanding this step of implementing data mining with Python is more understandable than other steps. In this step, we first classify the data to build a model that can be used to predict unknown categories. The following is an example of a classification code in Python:
It is necessary to know that the data classification step of the data mining implementation steps with Python has the following algorithms:
- Decision Tree
- Simple Bayes (Naïve Bayes)
- Multi-Layer Perceptron Neural Network
- Support Vector Machine
- Nearest Neighbors (K-Nearest Neighbors)
- Ensemble Learning Methods
It is essential to understand that one of the data classification algorithms is the regression algorithm, which examines the relationships between data and its modeling. The purpose of using this algorithm is to predict the value of a continuous variable based on the values of other variables. Which has two types:
- Linear Regression
- Logistic Regression

Step 3: Clustering
This step of the data mining implementation with Python is performed automatically, dividing the data into categories that contain similar members. The intended similarity varies depending on the application, the result, and the type of analysis, so that in each category, the members are both similar to and different from those in other categories.
The purpose of this step in implementing data mining with Python is to identify a similar set of items within the input data, where the number of clusters serves as the criterion for clustering, and to determine which cluster is more desirable, depending on the algorithm, and ultimately to find the individual.
The primary difference between clustering and classification is that clustering is used to describe data. In contrast, classification is used to create a predictive model that can classify data and predict which class a newly entered data point belongs to. In the clustering stage, two algorithms are used:
- K-means algorithm
- DBSCAN algorithm
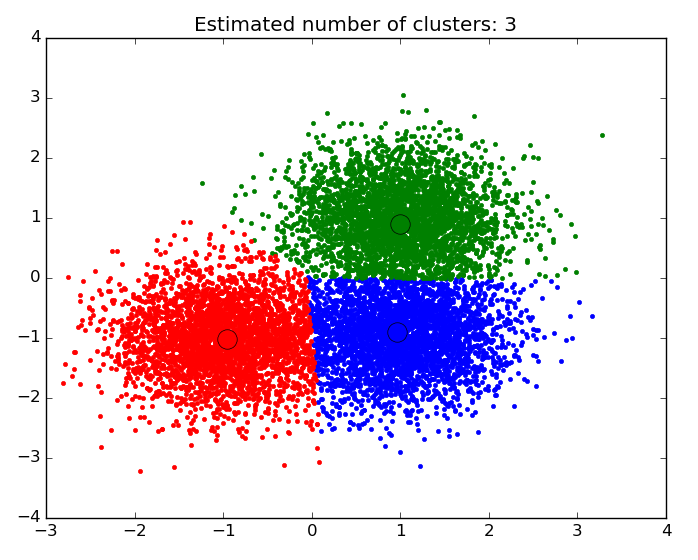
Step 4: Discover recurring patterns and association rules
The fourth step in implementing data mining with Python is discovering repetitive patterns and association rules. The purpose of association rules is to find significantly correlated items.
For example, one can examine the transaction of purchased goods to obtain a combination of goods that are usually purchased together.
To achieve this goal, the question must be answered: if a group of items is in the same transaction, which item seems to be in the same transaction with them? Therefore, the function that extracts this Rule from the data is called the associative function, and the best measure of correlation is the Pearson correlation coefficient, which can be obtained by dividing the covariance of two variables. The following Command clearly states the calculation method:
1 2 3 4 5 | <span style=“font-size: 16px;”>from numpy import corrcoef corr = corrcoef(data.T) # .T gives the transpose print corr</span> |
The result of this Command is a matrix containing correlations, the rows of which represent the variables and the columns of which are observations, and each member of which represents the correlation of the two variables.
It is essential to understand that the correlation becomes positive when two variables increase together and becomes negative when one variable increases while the other decreases. But when the number of variables is high, a Graph can be drawn with the following Command:
1 2 3 4 5 6 7 8 | <span style=“font-size: 16px;”>from pylab import pcolor, colorbar, xticks, yticks from numpy import arrange pcolor(corr) colorbar() # add # Arranging the names of the variables on the axis xticks(arange(0.5,4.5),[‘sepal length’, ‘sepal width’, ‘petal length’, ‘petal width’],rotation=–20) yticks(arange(0.5,4.5),[‘sepal length’, ‘sepal width’, ‘petal length’, ‘petal width’],rotation=–20) show()</span> |
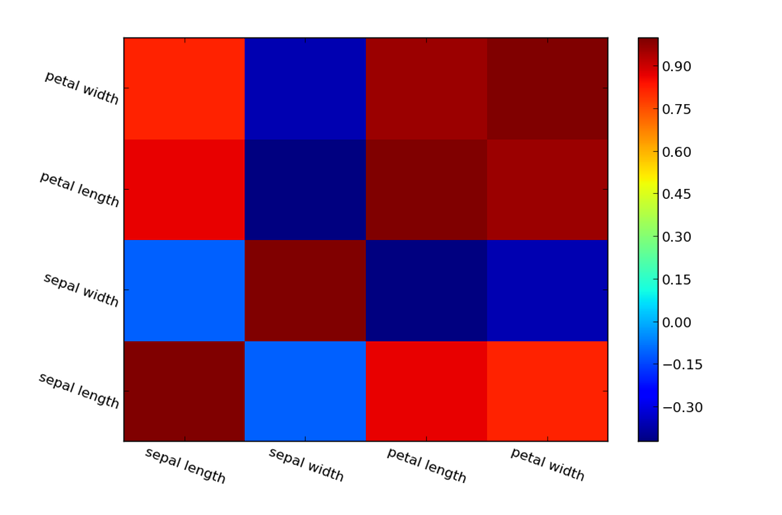
The result of the above Command is the following diagram:
Association Rule algorithms
- Apriori algorithm
- FP-growth algorithm
Step 5: Model evaluation methods
The last step in the implementation of data mining with Python is model evaluation methods, which include the following:
- Evaluation of classification models
- Evaluation of regression models
- Evaluation of clustering models
- Evaluation of recurring patterns and association rules
We hope you find this helpful article on the Python Data Mining Tutorial.