
What Is a Data Pipeline — Understanding Its Role and How It Works
Data Pipeline: You probably need a data scientist to run a state-of-the-art business or online store. If you produce a lot of data but do not think you need a data science expert, you are not yet familiar with this technology area.
Data science has been in the business dictionary since 2001. William S. Cleveland continued this by introducing it as part of the field of statistics. Until Google’s senior economist, Hal Varian, offered a new perspective on the science in 2009.
He believed that collecting and analyzing data would transform modern business.
What is a Data Pipeline, and what does it do?
Today, data scientists are developing machine learning algorithms to solve complex business challenges.
These algorithms help you perform the following processes:
- They make fraudulent predictions more accurate.
- Identify consumers’ and buyers’ motivations and desires with precision. This helps to raise brand awareness, reduce financial burdens, and increase marginal revenue.
- Predict future customer demand and help business executives spend liquidity in the right places.
- They help marketers personalize each customer experience based on their tastes and needs.
- To achieve these results, data pipelines are critical pieces of the puzzle.
What is a data transfer bus?
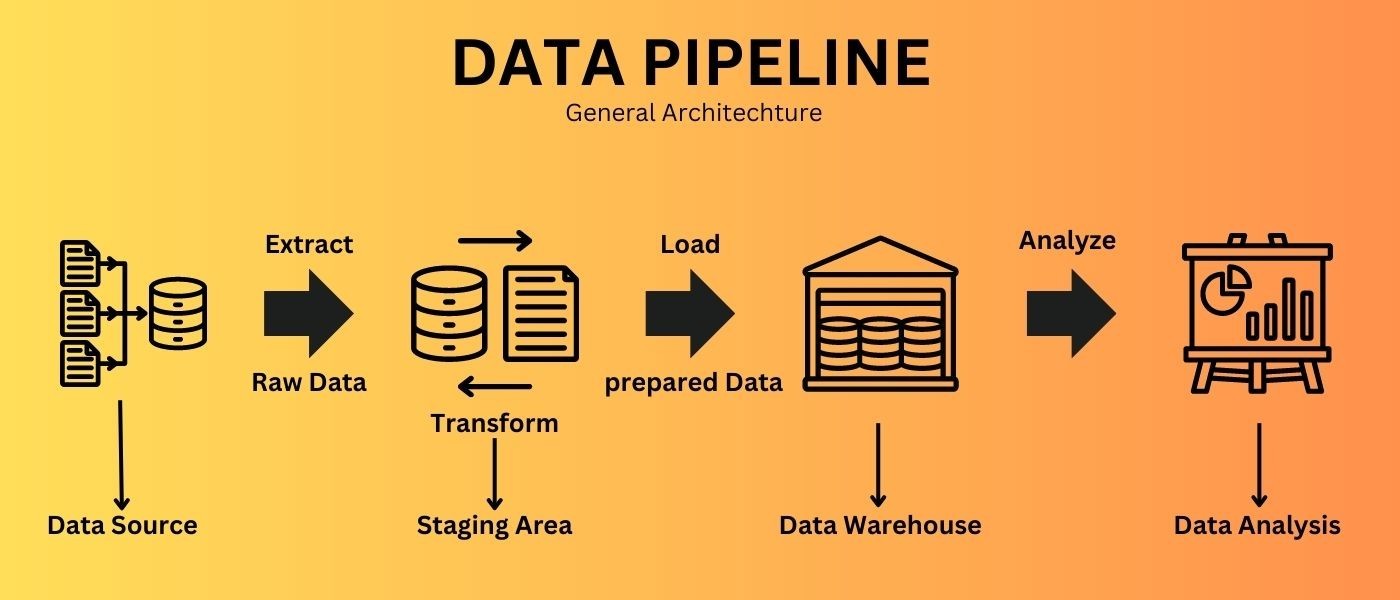
- The Data Pipeline is a set of steps that transmit raw data from one source to another. In business intelligence, a resource can be an exchange database, while the destination is usually a data lake or a data warehouse. The destination is where the data is analyzed to reach the business perspective. In the source-to-destination path, the data is refined to prepare it for analysis.
Why do we need a data bus?
- Using the cloud means that a modern organization uses a set of applications to manage various tasks. The marketing team may use a combination of HubSpot and Marketo to automate marketing, the sales team may rely on Salesforce to execute the strategic plan, and the product team may use MongoDB to store customer feedback.
- Since each team uses its own solutions, there is data fragmentation across tools and errors in results stored in data silos (repositories).
- Data warehouses can make even a simple fetch from a business perspective, like the most profitable market, difficult. You may encounter errors, such as data redundancy, if you try to manually fetch data from multiple sources and integrate them into an Excel spreadsheet. In addition, the effort required to do this manually depends on the complexity of the IT infrastructure.
- Also, transferring data from real-time sources, such as data streams, complicates the issue. Data gateways combine data from various sources into a single destination, enabling rapid analysis and business insights.
Elements of a data transmission bus
First, you should examine the key components of a typical data bus to better understand how a data transfer bus prepares an extensive data set for analysis.
Source
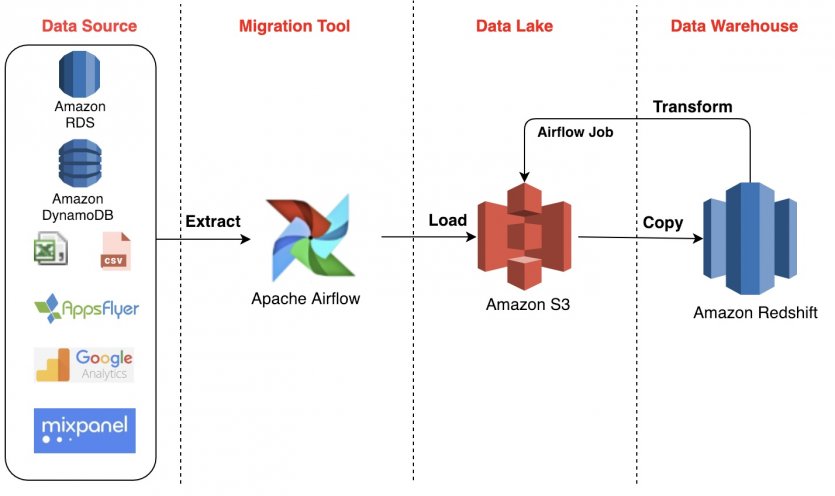
- A data bus extracts data from various sources, including relational database management systems (RDBMS), CRMs, ERPs, social media management tools, and even IoT sensors.
Destination
- The endpoint is the data transfer bus, where all extracted data is discharged. Often, the destination for a data bus is a data lake or data warehouse, where data is stored for analysis, but this is not always the case. For example, data can be sent to data visualization tools for analysis.
Data circulation
- The data changes as it moves from source to destination. This data transfer is called data flow. One of the most common methods of data processing is ETL (extraction, transformation, and loading).
Processing
- These steps include extracting data from sources, converting it, and transferring it to a destination. In the processing stage, it is decided how the data will be circulated. For example, what extraction process should be used to capture the data? Two standard methods of extracting data from sources include batch processing and ongoing processing.
Workflow
- Workflow is about sequencing tasks in a data bus and their interdependence. These dependencies and sequencing decide when to run a data bus. In a data transfer process, the upload process must be completed before the download begins.
monitoring
- A data transfer bus requires constant monitoring to ensure accuracy and prevent data loss. Its speed and efficiency should also be monitored, especially as data volume increases.
How is a data transfer bus built?
- To build a data transfer bus, an organization must decide how to extract data from resources and transfer it to its destination. Batch processing and streaming are two common ways to do this. After transferring the data to the intended destination, the conversion process (ELT or ETL) must be decided. This is just the beginning of building a data transfer bus. There are several other things to consider when building a low-latency, reliable, and flexible data transfer bus.
Do you need a data scientist to build a data transfer bus?
There are different views on this. Data scientists have a good job market, but no one knows what evidence they need. To address this ambiguity, the Open Group (IT Industry Consortium) introduced three certification levels for the Data Scientist title in early 2019.
To obtain these certifications, applicants must demonstrate their knowledge of programming languages, large-scale data infrastructure, machine learning, and artificial intelligence.
Until recently, data scientists needed to build a data bus, but today, with solutions from companies like Xplenty, you can create a data bus without coding knowledge.
Do you have to provide a dedicated data gateway yourself?
Some large companies, such as Netflix, have developed dedicated data gateways, but building one is time-consuming and requires extensive resources. In addition, such a solution requires constant maintenance, which increases costs. The following are some of the most common challenges faced by organizations in building data transmitters within the organization:
Connections
A modern company is likely to add new data sources as it progresses. Each time a new data source is added, it must be integrated into the data transfer bus. This integration may cause problems due to insufficient API documentation and differences in protocols. For example, a company instead
REST API Use SOAP API. Also, APIs may change or crash, so they must be constantly monitored. As the complexity of data resources increases, you will need to devote more time and resources to maintaining APIs.
Delay time
The faster the data transfer bus can transfer data to the destination, the better the business intelligence performance. However, extracting real-time data from several different sources is not easy. Some databases, such as Amazon Redshift, are also not optimized for real-time processing.
Flexibility
The data bus must be able to handle changes quickly. These changes can appear in various data forms or API ups and downs. For example, changes to an API may cause unexpected situations that the data bus may be unable to handle. You must be prepared for such scenarios to avoid disrupting the data transfer bus.
Centralization
Intra-corporate data gateways are usually maintained by a group of central IT members, including programmers, who are responsible for building and maintaining them. This raises two major concerns: the cost of hiring a dedicated engineering team can be high, and this approach centralizes data processing, which is inefficient.
Superconfigured data gateways have significantly reduced costs, so any business can create its own data gateway within minutes and start collecting business insights. Decentralized data processing can be a significant advantage for increasing operational efficiency.
A case study of using a new solution to build data transmissions
Xplenty provides an intuitive, user-friendly platform that enables organizations to create their own data transfer bus in minutes. This data integration platform can meet the needs of specialized engineering teams and address the time-consuming burden of building and maintaining these systems.
This system is compatible with most data storage devices and SaaS platforms, and REST APIs enable you to connect almost any data source to a data transfer bus.
FAQ
What exactly is a data pipeline?
A data pipeline is a sequence of processes that extracts raw data from one or more sources, transforms or processes it, and then loads it into a target system for further use.
What are the main stages of a data pipeline?
Typical stages include data ingestion (collecting from sources), data transformation (cleansing, formatting, aggregating), and data loading into the destination (data warehouse, data lake, analytics store).
Why do organizations use data pipelines?
They automate and scale data collection and processing, integrate data from multiple sources, improve data quality, eliminate manual effort, and enable analytics, reporting, real-time dashboards or machine learning on consolidated, clean data.