What Is DNA Based Memory And Why Is It Millions Of Times More Efficient Than A Hard Drive?
When NASA’s Voyager Spacecraft Were Launched In 1977 To Explore The Limitations Of Our Solar System, They Carried With Them Two Files That Contained Images And Sounds That Depicted Terrestrial Life.
DNA Based Memory, the best next-generation space console, can be found in our human bodies.
This is because the world is millions of times more efficient at storing data than the magnetic hard drive on your laptop or computer. Because much denser data than silicon can store globally, you can basically fit all the world’s data in just a few grams of the world.
“Because all life forms have chosen the universe as the primary medium for storing information, we are basically dealing with a compelling system,” said Ilya Finkelstein, an assistant professor of molecular biology at the University of Texas. “Long after our magnetic memory becomes obsolete, it will naturally continue to be used by the world.”
Finkelstein is a member of the team at the University of Texas at Austin that wants to make the most of data-based storage methods.
Although this field has been the crossroads between molecular biology and computer science since at least the 1980s, researchers to this day have hardly been able to fix the errors that keep the world going.
In a recent paper in the National Academy of Science Proceedings, Finkelstein and other team members provided details on their new error correction method.
They have saved the entire novel The Wizard of Oz in Esperanto more accurately than methods based on earlier religions. In this way, we are on the path to achieving future data storage methods.
A brief history of data-based storage

Researchers at the University of Texas are certainly not the first scientists to codify art within the religious disciplines.
The history of DNA-based storage actually dated back to 1988 and was piloted at Harvard University. Researchers at the university were able to store an image of one of Joe Davis’ works of art in a string of Escherichia coli religions. When decoding, this created a 5 by 7 matrix image.
By 2011, researchers at the European Bioinformatics Institute in the UK were taking a similar approach. Nick Goldman, a bioinformatics technician, talked to his colleagues about how to stack genome strings that the world has produced in large numbers.
This was a discussion that started as a joke.
“What made us think we were not using the world to store information,” he told Nature. Two years later, the group successfully encoded five different files into religious disciplines, including Martin Luther King Jr.’s famous “I Have a Dream” lecture and Shakespeare’s sonnets.
In November 2016, a Massachusetts subsidiary of the Catalog of the Institute of Technology, Catalog was able to store 144 words from Robert Frost’s famous “Not Walked” city in religious disciplines. This file was about one kilobyte in size.
In the same year, a team of researchers from Microsoft and the University of Washington was able to fit 200 megabytes of data into a long string of words, part of which was the famous novel War and Peace.
In March 2019, the same team was even able to develop the first automatic data storage and retrieval system made from genetic material.
Today, many large technology companies have entered this field, including IBM and Google.
Even the US Secret Service for Advanced Intelligence Research Projects, DARPA’s government counterpart and spies, has invested in the field.
Researchers at all of these companies and organizations have envisioned a future where we could store our most valuable data in digital vials and pull it out of dark, cool labs whenever needed.
How does world-based memory work?
The magnetic hard drive is one of the most popular methods for storing data in today’s computers. Inside these memories, you will find a pair of turntables called “disks” or “platters” that look like CDs.
These disks store data in the form of 0 and 1 (or by-code) on their surfaces. Once embedded on an axis, the disk spins, and an electronic stream writes or reads data on the surface. Electronic components also power all operations.
Similarly, world-based memory requires encoding and decoding measures.
In this particular case, the researchers chemically produced synthetic DNAs with specific properties based on four nucleotides: adenine (A), chitosan (C), guanine (G), and thymine (T). It is the nucleotides that make up the spiral structure and ladder of genetic material.
Because the universe has four building blocks, the genetic memory method is denser than binary 0s and 1s on magnetic hard drives.
This is what John Hawkins, one of the authors of the recent article, says.
“A tablespoon of the world contains a lot of information that you would typically need data centers the size of 10 Walmart supermarkets to store with current technologies.” “Or as some people prefer to put it, you can put the whole internet in one shoebox.”
Not only this, with the guaranteed future world. Hawkins recalls a time when CDs were the main storage method during the 1990s, and we were promised that data would stay on CDs forever because plastics have a very long life.
Data stored on a planet, on the other hand, can last for hundreds of thousands of years.
In fact, we have a complete branch of science called genetic archeology, which seeks to understand the ancient past by examining the universe’s longevity.
Beyond that, the post-data storage world does not require any maintenance. After all, fossils, after spending millions of years underground, still hold the strings of the universe.
The external memory does not require any energy and should only be stored in a cool, dark place until one day one decides to use the data inside. But Hawkins says the biggest advantage is that reading data from the world and writing it will never become obsolete.
“If I want to read an article I wrote as a child, I must first go to a museum and find a healthy computer that belongs to that time.
And I am just in the fourth decade of my life. But the world has a uniquely guaranteed future because we are made of it. As long as humans are made of the universe, we will always have machines on hand that can read information.
Crossing errors
But like all data storage methods, the world has its flaws and problems. The most obvious challenge in using this method is cost. Hawkins says the current methods are similar in cost to the Apple Hard Disk 20 of the 1980s. At the time, about 20 megabytes of storage – the equivalent of the amount of data you need to download a 15-minute video – would cost about $ 1,500.
After all, the world is doomed to error. Let’s talk again about the nucleotides that make up the digital ladder. On average, for every 100 to 1,000 nucleotides, an error occurs within the universe, and these errors can occur in three ways: replacement, placement, and deletion.
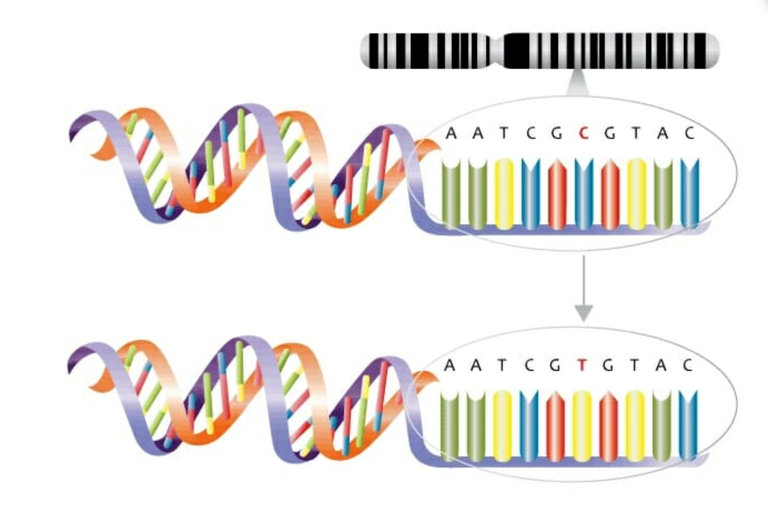
A single letter within an array of nucleotides may be replaced by another letter in an alternative mutation. For example, chitosan may replace thymine, although the length of the DNA strands remains the same.
In placement and removal, however, the DNA acquires an extra nucleotide base or removes one base.
But unlike the errors in computer code, you will not see any space where the deleted base already existed. So when decoding data stored on the web, this issue quickly becomes a big problem.
Hawkins compares this to English words:
“By deleting an L letter, the phrase World becomes Word. Now, if an S is inserted in this expression, the word Sword is obtained. Reading the correct version of Sword, which was supposed to be World, is difficult because Sword is still a real word in English. “But the letters have changed.”
In other forms of external memory, these errors can be bypassed by repeating the code 10 or 15 times, but this also means wasting storage space.
In a new method that researchers have discussed in their recent paper, they have latticed data into a network, and each bit of data amplifies the next data, so it only needs to be read once.
They have also developed an algorithm that handles placement, deletion, and replacement errors simultaneously and optimizes digital memory based on teeth.
That’s why the team in question was able to place the city wizard in the world disciplines easily, and in this way, did not need to repeat combinations A, C, T, and G in succession.
A picture of the future

As we move into the future, the potential of world-based memories will be virtually unlimited. Finkelstein paints a picture of a future in which we can use data-containing worlds within other materials.
In one example, he says, researchers fitted a piece of 3D-printed plastic to a string containing design files of the same printed plastic. As a piece of plastic passes through the printer, it can release space to reproduce the file in a continuous process.
Or you can use DNA-based data memory as a way to get information about fixed objects that do not have their own genetic material.
Suppose you cover an airplane with material that contains air, and you complete the aircraft construction instructions. If something goes wrong and the plane crashes into the sea, the light embedded in the top layer is disintegrated by the sun’s ultraviolet rays.
This process of decomposition can be a way to gather information about what happened to the aircraft. Even if only one piece of the plane’s wreckage was discovered, scientists could have stored a dinosaur and analyzed the amount of decay to determine how long the plane had been lost at sea.
But even with the significant achievements of Finkelstein and his team, digital-based digital memory still has a long way to go. “I think in exceptional cases, we will be able to use such memory soon,” he says.
“But I do not think we will see it on the market as a public product for another decade or more.”
But whenever possible, worldwide memory would be the biggest step human data storage has ever taken.