
What Is The Future Of Neural Networks?
Deep Learning Is A Vast Field That Revolves Around A Centralized Algorithm That Is Modified By Millions Or Even Billions Of Variables.
This big algorithm is called a neural network. Statistics show that new techniques and methods enter this field every year, each of which has brilliant advantages.
However, deep learning in the current era can be divided into three basic learning paradigms.
At the heart of each of these paradigms, new attitudes towards learning have their capacity and subtleties and try to increase the power of knowledge and the depth of understanding.
In this article, we will learn three paradigms expected to be noticed by researchers and companies in the next few years.
hybrid learning
Is it possible that we can invent techniques and methods in the field of deep learning to overcome the limitations that surround supervised and unsupervised learning so that we can match and use large volumes of unlabeled and unused data? ? On the face of it, doing such a thing seems complicated, because we need more advanced and, of course, more complex paradigms.
composite learning
How can different models or components be connected creatively to create a composite model that includes other parts?
Reduced learning
How can models’ size and data flow be reduced to improve performance and simplify the deployment process while maintaining or improving predictive power?
The perspective of deep neural networks shows that the future of deep learning is from those three paradigms we mentioned, and interestingly, each of them is related to the other.
hybrid learning
This paradigm attempts to overcome the limitations surrounding supervised and unsupervised (self-supervised) learning. Supervised and unsupervised machine learning models face problems such as lack of access to high-quality data sources, high cost of accessing labeled data, and lack of sufficient information about a specific business domain. Blended learning seeks to answer how we can use supervised methods to solve problems around unsupervised models.
For example, semi-supervised learning (semi-supervised learning) has received attention in the machine learning community due to its excellent performance in solving problems with supervised patterns and especially less labeled data. For example, a well-designed semi-supervised adversarial generative network can provide correct output with over 90% accuracy on the MNIST dataset (an extensive database of handwritings) after viewing only 25 training examples.
Semi-supervised learning is designed for datasets where not much-unsupervised data is available, and only a small amount of supervised information is available to researchers. While a supervised learning model is traditionally trained on one part of the data and an unsupervised model on another, a semi-supervised model can combine labeled data with insights extracted from unlabeled data.
It shows the issue. SGAN Semi-supervised Generative Adversarial Network is an adaptation of the standard generative adversarial network model. Here, a discriminator that shows both 1/0 outputs and determines whether an image is produced indicates the class output (multi-output training).
The above technique was developed based on the idea that a model can recognize the difference between natural and produced images through discriminant learning techniques and then understand their structure without using labeled data.
Next, to improve the output, a small amount of labeled data is provided to the model to enhance the performance so that the semi-supervised models can provide the highest level of performance with the least amount of supervised data.
In addition, adversarial generative networks are effective in another field of hybrid learning, self-supervised learning, in which unsupervised problems are explicitly provided to the model as supervised ones.
Generative adversarial networks artificially generate supervised data by introducing a generator and creating labels to identify the real/generated images so that a self-observing work process can be completed as a supervised work process. It is almost similar to what we do in the sessions of discrete math tests, and we try to reach the answer through arguments and induction.
Another method is to use encoder-decoder models for compression. In its simplest form, the above technique describes neural networks with a limited number of intermediate nodes forming dense bottlenecks. Here, two components are located on both sides of this bottleneck and are known as coder and encoder.
The network is trained to produce the same output as the vector input (a synthetic supervised task from unsupervised data). Since a bottleneck is deliberately placed in the middle, the network cannot pass information passively.
Instead, it must identify the best ways to keep the input content in a small unit so that the decoder can logically decode the information on the other side of the bottleneck.
To explain this issue, let us mention an example. When you have practical work experience with a programming language like C Plus Plus and decide to enter a software bachelor’s degree, the C Plus Plus teacher will raise a problem in the class. You will quickly solve it based on your previous knowledge, even if the solution you provide is not optimal But when the teacher restricts you to solve the problem only based on the information he has taught so far, then you have to think a little so that you can provide the best solution for the problem. What the encoder and decoder technique does is the same.
After completing the training, the encoder and decoder are separated. Here It can be used to receive compressed or encrypted data to transfer fewer data without losing it. They can also be used to reduce data dimensions.
Consider an extensive collection of texts, for example, comments entered into a digital platform. By applying some clustering or multiple learning methods, we can generate cluster labels for text toe can use them as labels later (provided that the clustering is done well).
To be used. The data is unlabeled here, and the lowest possible value is used. After each cluster is interpreted (for example, cluster A represents comments that reflect complaints about a product, cluster B reflects positive feedback, etc.), a deep natural language processing architecture such as BERT can be used to classify new texts into these clusters.
Here, the dual goal is to create an application to convert unsupervised processes into supervised processes. In the era where most of the data is unlabeled, we have to use creative approaches to overcome the limitation of supervised and unsupervised learning algorithms by relying on hybrid learning.
Composite Learning
Blended learning has a different approach from the combined mode, and as its name suggests, it does not seek to use the knowledge of one model but to use the understanding of several models. The idea behind the formation of the compound learning technique is that if we can train deep learning continuously through unique combinations of static and dynamic information, we will eventually gain a deeper understanding and better performance.
Transfer learning is a clear example of compound learning. It emphasizes the idea that the weights of a model can be borrowed from a model already trained for a similar task and edited in such a way as to perform and be used for exceptional work. Pre-trained models such as Inception or VGG-16 are built with architectures and weights designed to discriminate between several different classes of images.
For example, suppose we intend to train a neural network to recognize animals (cats, dogs, etc.). In that case, it is natural that we do not teach a convolutional neural network from the beginning because it will take time to achieve the desired results. In contrast, we choose a pre-trained model such as Inception, which already has the basics of image recognition, and then provide the model with a few more datasets for training.
Similarly, in placing words in natural language processing neural networks, we try to use physically and semantically closer to each other in a closed training set that is supposed to describe relationships (for example, the words apple and orange are less semantically distant)—compared to apples and trucks for the same model).
The goal is to make the semantic recognition and mapping process more meaningful and faster. Therefore, in the composite model, the abilities of several models are tried to be used to build a robust model.
In such a paradigm, models gain a better understanding of concepts in the competition to provide results. In the scenario based on compound adversarial generative networks, which are based on two neural networks, the productive goal is to deceive the discriminator, and the discriminator’s goal is not to be deceived.
The competition between models is called adversarial learning, which should not be confused with another type of adversarial learning that refers to designing destructive inputs and exploiting limited decision boundaries in models. In negative examples, intakes may be prepared for the malicious network. Conceptually, it is impossible to recognize their validity and correctness for the model, but the model still misclassifies them.
Adversarial learning can stimulate different models so that the performance of other models shows the interpretation of one model. It is necessary to explain that there is still a lot of research in the field of adversarial learning.
On the other hand, there is competitive learning, similar to adversarial learning but is done on a node-to-node scale so that nodes compete with each other for the right to respond to a subset of input data.
Competitive learning is implemented in a competitive layer, where a set of neurons are identical except for some randomly distributed weights. The weight vector of each neuron is compared with the input vector, and the neuron with the most similarity is activated as the winning neuron (output = 1), and the rest are inactive (work = 0).
This unsupervised technique is the main component of self-organizing maps and feature discovery.
Another exciting example of blended learning is the search for neural architecture. In simpler terms, a (usually iterative) neural network learns in a reinforcement learning environment to create the best neural network for the data set and find the best architecture for you.
Ensemble methods are one of the fundamental components of blended learning. Deep Ensemble methods have been shown to perform well, leading to the growing popularity of end-to-end models, such as encoders and decoders.
A large part of compound learning is finding unique ways to make connections between different models. It is based on the idea that a single model, even a vast model, cannot perform as well in all conditions as many smaller models/components, each in part. They specialize in their work. For example, consider the task of building a chatbot for a restaurant.
We can divide this process into three parts: pleasures/chatbots, data retrieval, and execution. Next, let’s design a model that specializes in handling these processes or create a model where each part is responsible for managing a specific task.
I suggest that researchers focus on building composite models for processing diverse data types, such as videos and 3D data. Surprisingly, the hybrid model can perform better while taking up less space. Furthermore, these types of nonlinear topologies can be easily created with tools such as application programming interfaces (APIs) of libraries such as Keras.
Reduced learning
The size of models, especially in natural language processing, has become one of the hottest topics in deep learning, and so far, much research has been done in this field. The latest GPT-3 model has 175 billion parameters; comparing it with the BERT model is like comparing a bicycle with an airplane (Figure 5).
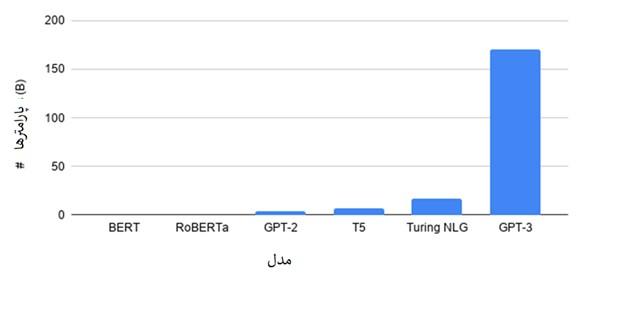
Figure 5
As you can see in Figure 5, GPT-3 is quite powerful. We are moving towards an AI-driven world, where an intelligent fridge can automatically order groceries, and drones can take over many urban tasks.
In addition, we are witnessing powerful machine learning methods gradually entering the hardware components of personal computers, smartphones, and even Internet of Things equipment. All these components require a lightweight, intelligent algorithm. An algorithm that can build smaller neural networks while maintaining performance.
It seems that, directly or indirectly, almost everything in deep learning research is moving towards reducing the number of parameters associated with improved generalization and, thus, improved performance.
For example, introducing convolutional layers has helped reduce the number of parameters neural networks require to process images. So that the same weights are tried to be combined, and the neural networks process the sequences better and with fewer parameters.
Embedded layers explicitly map entities to numerical values with physical meanings so that no extra burden is placed on parameters.
For example, it is possible to use the regularization technique when you feel that the data is overfitting and the performance has decreased. For instance, if the dropout layers encounter failure, it is possible to evaluate the criteria and make changes to the parameters in the L1 and L2 layers.
You can use the regularization technique of the first layer and the second layer so that the network optimally uses all its parameters and make sure that none of the layers become too large and that each one provides the highest and highest quality level of information.
By creating specialized layers, networks require fewer and fewer parameters for larger and more complex data. Other newer methods also explicitly seek to compress the network.
Another critical issue with reduced learning is pruning. Pruning the neural network seeks to remove synapses and nerve cells that have no value for the network’s output. Through pruning, networks can maintain their performance.
All these efforts aim to compress and miniaturize models that are supposed to be deployed on consumer devices such as smartphones.
These considerations made the Google Neural Machine Translation (GNMT) system improve the performance of the Google Translate service. So today, it is a service with high accuracy in translation, which can be used even offline.
Today, part of the research on deep learning revolves around deductive learning, and they try to use the best performance criteria for a specific problem so that the process of establishing a model is done in the best way.
It is necessary to lighten the workload of the models; for example, the hostile inputs we mentioned earlier are malicious inputs designed to trick a network. For example, spray paint or stickers on signs can trick self-driving cars into speeding. To solve this problem, ensure that the model can interpret and understand things that may not be included in the data set.
last word
Blended learning seeks to cross the boundaries of supervised and unsupervised learning. Methods such as semi-supervised and self-supervised learning can extract valuable insights from unlabeled data and help us use unsupervised data more efficiently and optimally.
As tasks become more complex, blended learning breaks down tasks into simpler components. When these components work together or contrast, the result is a powerful and efficient model.
At the current stage, reduced learning has not received much attention because the eyes are directed toward deep understanding. Still, shortly, when the paradigms lean towards deployment-based design, we will see the growth of research in this area.