
Security Plus; How To Use Fault Tolerance Mechanisms?
A Big Part Of Ensuring High Availability Is Creating Redundancy In All Areas, Including Hardware. Redundancy Should Be Applied To Equipment Such As Servers, Hard Drives, Network Cards, Communication Links, Etc.
Snapshots
Fault Tolerance Mechanisms, Many organizations, use virtualization technology to build virtual machines (VMs) that run on servers on the network. You can create a virtual machine snapshot that provides a quick backup of the system status and configuration with virtualization software. The advantage of Snapshot is that you can quickly restore everything to a backup.
However, snapshots also have problems. For example, one of the drawbacks of images is that you lose all the changes made to the system after taking the pictures, so you have to use the snapshots in certain situations.
Snapshots are a point-in-time copy of a disc or set of disks, as far as backup is concerned. For example, solutions such as the VSS header Volume Snapshot Service, known as Shadow Copy, allow vendors to back up to a single disk.
When the backup starts, it backs up the snapshots and allows users to modify the files on the disk when the backup is done because they are technically preparing the images. Any changes to the files that occur during the backup are recorded and then recorded in the backup.
Schedule a backup
Most network administrators prefer to have late-night backup operations automated or enabled from home. That’s why they plan their backup operations so that they do not need to be in the office overnight to get started. Most backup software supports backup scheduling, and this is one of the features that you should look for when choosing a backup software.
It would help to create a backup plan when planning your backup operations. A backup plan includes a list of data prepared with each backup process and the type of backup (incremental, partial, or complete). You should also make sure that a backup program is included in this plan.
For example, you might decide to make a full backup of your data files and email data every Saturday at noon. Backing up your data files and e-mail servers are expected at this time, and when combined with partial backups, it provides a powerful way to protect your data so that backups include the latest changes.
When developing your backup plan, make a detailed schedule of resources on the server (such as folders, databases, or emails) and their contents. Also, plan how often this information should back up.
In addition to the usual information about network diagrams, firewall rules, server settings, and the like, top companies also make backups to restore everything to its original state without any problems.
You must be a member of the Administrators or Operators Backup group to be able to back up your Windows operating system. You can also use the Backup file and directories section to get the necessary backup permission.
Back up and restore data on the Windows server.
In this exercise, you will learn how to backup files on your Windows server using Windows backup software and how to recover a file after accidental deletion. Be sure to watch the video of this exercise available in online sources and in this book.
- Go to the ServerA virtual machine. Selecting Manage | Add Roles and Features Install the Windows Server Backup feature.
- After installing the Windows Server Backup software, ensure you are still in the Server Manager window. More Tools | Select Windows Server Backup.
- Select Local Backup on the left.
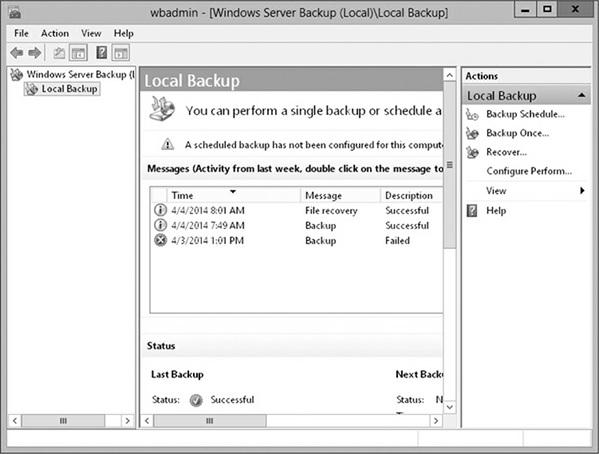
4. To back up the LabFiles \ PacketCaptures folder, select the Backup Once option in the Actions section on the right.
5. Select the various options to specify your backup settings and click Next.
6. Select the Custom option to select the files you want to back up, and then click Next.
7. Click Add Items to add items that need to be backed up. Expand the contents of drive C: by selecting the + sign, and then open the LabFiles folder.
8. To back up the PacketCaptures folder, select the box next to the PacketCaptures folder and click OK.
9. Click Next. To back up a file to another disk, select Local Drive and click Next.
10. Click the Backup button to make a backup. This process should only take a minute.
Recover deleted file
11. to Computer path Drive C: | labfiles | Go to PacketCapture.
12. In the PacketCaptures folder, select and delete a file called httptraffic. Cap.
13. Click Yes to confirm that you want to delete the file.
14. Close all windows.
15. To recover the deleted file, launch Server Manager and then Tools | Select Windows Server Backup.
16. Click on the Recover link in the Actions panel.
17. Select This Server to specify the backup to be saved on your local server, and then click Next.
18. Make sure you select the current date as the day the backup performs. Click Next.
19. Select the Files and Folders option to recover separate files from the backup, and then click Next.
20. On the left, click the plus sign (+) to expand through the backup folder structure, where you will see the PacketCaptures folder. Select the PacketCaptures folder on the left to display the files in that folder.
21. Select the HTTPTtraffic.cap file on the right to retrieve.
22. Click Next.
23. In the recovery options, select Original Location to recover the file from which made the backup initially. Click Next. Note that ACLs (licenses) will also retrieve.
24. Click Recover to start the recovery operation.
25. After the recovery operation is complete, click Close and close the backup software. Check if the files are now in C: \ labfiles \ PacketCaptures?
Geographical considerations
When planning for disaster backup and recovery, you need to consider some geographical considerations regarding your physical location.
- Offsite storage: Be sure to save a copy of your backup elsewhere in a disaster such as a fire, flood, or earthquake.
- Distance considerations: Off-site support is close enough that you can get it when you need it, but at the same time, it is far enough away that no catastrophe will affect your current location.
- Location selection: Be sure to choose a backup location equipped with emergency services. You should also ensure that the site receives prompt responses from companies such as the electricity company. Also, check the surrounding area and ensure it is not in a flooded area or an area with a high crime rate.
- Legal implications: When choosing a physical location for your site and backup tape, try to read the laws in that country or state that could affect how your data is accessed or managed.
- Data sovereignty: Make sure you know who owns the data. By storing data in a particular country or state, do you give a third party an implicit right to access the data? With cloud storage, you may want to know where your cloud servers are located and make sure your data is not in conflict with the law in your own country or the country of your choice.
Implementing the Fault Tolerance Mechanism
A big part of disaster preparedness is ensuring that systems are up and running correctly, especially when the hardware has a problem. For example, companies need to ensure that there are at least two power supplies on one server so that if one power supply fails, the other power supply enters the circuit, and the server functions correctly. This section will get acquainted with different ways of tolerating error and redundancy.
What is redundancy?
A large part of the cybersecurity flexibility mechanism is the implementation of redundancy about assets such as hard drives, network devices, and power supplies. These include having multiple power supplies on various servers or communication channels when a connection to an Internet service provider is lost. Redundancy ensures that investments do not become entirely inaccessible in the event of a problem.
When creating redundancy, especially when it comes to data redundancy and services, you need to determine whether you want to use in-house solutions to achieve redundancy, which is a solution in your physical network, or whether you want to use a meta-centric mechanism.
For example, in the case of email servers, the redundancy solution could be to have an internal backup email server or an email service hosted in the cloud. Note that you can transfer all your resources to the cloud host.
Disk redundancy
Hard disks are the first component to look out for when implementing redundancy solutions. It is to protect the data when the server hard drives fail. There are two main ways to achieve hard drive redundancy that you should not ignore.
- Redundant array of inexpensive disks (RAID): You can use the RAID solution to protect your data against hard disk failure. RAID lets you create volumes that use multiple hard disks to provide data redundancy. For example, you could make an asymmetric RAID volume that saves data to two physical disks if one fails.
- Multipath: Another way to add redundancy to data or disks is to use a multi-path mechanism, also known as multi-path input/output. Multipath is the creation of multiple paths to access data at any location that may store. For example, suppose you store data in a SAN. In that case, your server may have various fiber channel controllers connected to the SAN, consisting of multiple switches, so that there will be multiple paths to access the data in the SAN.
Network redundancy
Data redundancy is essential when implementing disk redundancy solutions such as RAID, but you should also have redundancy for other network components. The following are two critical technologies for redundancy in network components:
- Load balancers: A load balancer is a component that distributes workload across several features to deliver a request. For example, you can put multiple web servers behind a load balancing component that sends requests to different servers. If you add another web server to the load balancer, the workload is distributed between the servers. If one of the servers crashes, the load balancer detects this and distributes the other requests between the remaining servers.
- Network interface card (NIC) teaming: One of the most popular operating systems and server features allows you to integrate the bandwidth of multiple network cards. One way to speed up packet processing is to have various NICs as a single component. If one of the NICs fails, the other remaining NICs can use it to send and receive traffic. The above approach is used in connection with scenarios in which a lot of traffic needs to be managed. Ic.
Redundancy on Power
As mentioned, it is essential to put redundancy in connection with electricity. There is still a way to supply power to critical assets such as servers and routers in a power outage.
- Uninterruptible Power Supply (UPS): A hardware component provides an uninterruptible power supply in a primary power failure. UPSs have batteries that charge as soon as the power goes out and are ready to power any connected device such as servers. Battery life is relatively short and is used to accurately turn off appliances that are connected to the UPS or until the generator has the opportunity to start.
- Generator: An alternative power supply that usually runs on gas or propane to provide backup power in a mains failure. The generator can be started manually or automatically when the power goes out.
- Dual supply: You can have multiple power supplies on your devices, such as servers, switches, and routers, so that if one power supply fails, the device will still have another power supply.
- Managed Power Distribution Units (PDUs): A component distributes electrical power over a network rack or computer. Managed PDU lets you supply power to your equipment.
Redundancy with Replication
Another technique for adding redundancy is duplicating data from source to destination at regular intervals. Here are two critical technologies that are used in connection with reproduction. There are common ones that use repetition:
- Storage Area Network (SAN): A storage area network is a group of storage drives connected by high-speed links. You can copy data from one SAN to another on another site using Replication, known as SAN-to-SAN duplication. The above approach ensures that the data is in different places, and there will be access to the data in the event of a disaster.
- Virtual Machines (VMs): You can copy virtual machines running on one server to another. Virtual machine replication technology lets you control which VMs are running. The above approach is a great way to ensure redundancy in virtual machines.
To take Security Plus, you must know the various disk redundancy, network redundancy, power surplus, and duplication solutions. Mainly related to RAID, multitasking, load balancing, NIC teaming, dual power supply, and UPS.
Non persistence and Diversity
Security Plus test raises questions about the instability and variability of cybersecurity flexibility. By definition, instability means data loss when a system shuts down, or an application closes.
The following are some of the factors that can help you achieve system stability:
- Return to known mode Programs such as Deep Freeze can restore the system to its previous state. With Deep Freeze, the administrator saves the current state of the computer and, after rebooting the system, returns to the protected form to undo the changes. It is a standard program used in computer labs. Another example is the Windows System Restore feature, which can use to return to the previous state.
- Last known-good configuration: Some tools allow you to go back to the previous well-known design. For example, Windows has a boot option that lets you return to the last time you logged in safely.
- Live boot media: Live boot media is an executable operating system that runs from a DVD or USB drive. Live media lets you run tools from the operating system, but note that data is not stored permanently after the system is turned off. For example, you can create a WinPE disk or a live version of Ubuntu that allows you to use the operating system you put on removable media to boot a system.
When implementing any of these redundancy technologies, make sure that the variety of solutions plays an essential role in the sustainability of the environment. Variation refers to the fact that there is always the possibility that some of the answers will attack; to solve this problem, you must use complementary solutions.
There are many ways to achieve security diversity as follows:
- You can use NIC teaming to connect redundancies to each server’s network cards, use clustering for high-throughput access to a database service, and use RAID on storage drives used to store database files.
- Use the products of different vendors to create variety. A great example of this is the firewall. Look for firewall products from other vendors at various network layers.
- Use different encryption algorithms and keys for each implementation so that if the encryption is broken or cracked, the other algorithm will protect the data.
- Use different types of security controls to protect your assets. For example, you should patch systems at endpoints (workstations), use antivirus / anti-malware software, use a host-based firewall, and make sure users are well-versed in computing and Internet techniques. Each of these controls increases the security of workstations.