What Are The Uses Of Apache Kafka And Apache Spark?
Apache Kafka is an open-source streaming platform developed by LinkedIn and donated to the Apache Software Foundation.
The goal of this project is to provide an integrated platform, high power, and low latency for instant data.
Its storage layer is a highly scalable, engineered (pub/sub) message queue associated with distributed transactions. Apache Kafka is the open-source processing infrastructure of a stream written using the Scala and Java languages.
Kafka and Spark are among the most important tools that machine learning engineers use extensively.
Apache Kafka
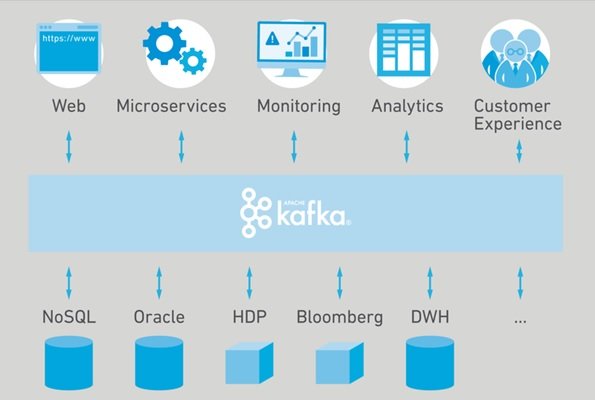
The project aims to provide a robust, integrated low-latency infrastructure for the immediate manipulation of input information. Its storage layer is basically distributed in large quantities and large scales for a server-queue architecture. Kafka is used for data processing (Stream Processing) and messaging broker (Message Broker).
In addition, Kafka allows connection to external systems (for input/output data) via Kafka Connect and provides Kafka Streams. Kafka works best for managing large volumes of data that are constantly being sent and there is not enough time to process and store it. In addition, Kafka is well able to manage errors.
How to use Kafka?
The first step in using Kafka is to build a Topic. From now on, new messages can be sent via TCP connection for storage in the new Topic. This can be done easily through clients that are designed in different languages and for different platforms. These messages must then be stored somewhere. Kafka stores these messages in files called Log.
New data is added to the end of the log files. Kafka has the ability to store incoming messages on a set of Kafka servers clustered together. If, for example, there are n Kafka servers in a cluster, the data associated with each message sent will be copied to all supported servers after being stored on the Leader server.
However, even if n-1 servers are decommissioned, the Topic data in question will still be available and usable.
Hence tolerance for error is well seen in Kafka.
Reading information stored on Kafka can also be done through clients. The message-consuming client, called the Consumer, must subscribe to a Topic to read the messages.
From now on, with the implementation of the Poll method, the data will flow to the consumer.
When defining a new Topic, it is possible to store related data in multiple partitions. In fact, Kafka stores all messages sent to a Topic in all partitions in the same order in which they were sent.
In this storage model, each partition is stored on a server and the other servers in the Cluster will copy the backup of that partition. This Kafka feature allows the consumer to receive information in parallel.
Apache Spark
Apache Spark is an open-source distributed computing framework. The software was originally developed by the University of California, Berkeley, the code of which was later donated to the Apache Software Foundation, which has maintained it ever since.
Spark provides an application programming interface for programming all clusters with parallel data parallelization and fault tolerance.
Spark uses the main memory to store program data, which makes programs run faster (unlike the mapping/reduction model, which uses disk as a storage location for intermediate data).
Also, another thing that increases the performance of Spark is the use of the cache mechanism when using data that is to be reused in the program.
This will reduce the overhead caused by reading and writing to disk.
An algorithm to implement in the mapping/reduction model may be divided into several separate programs, and each time the data is read from disk, it must be processed and rewritten to disk.
But using the cache mechanism in Spark, the data is read from the disk once and cached in the main memory and various operations are performed on it.
As a result, using this method also significantly reduces the overhead caused by disk communication in programs and improves performance.
What components are Spark made of?
Spark Core: The Spark Core contains the basic operations of Spark, including the components needed for task scheduling, memory management, error handling, storage system interaction, and more.
The Spark kernel is also home to the development of APIs that define RDDs, and RDDs are the core concept of Spark programming.
RDDs represent a set of items that are distributed over multiple computational nodes and can be processed in parallel.
The Spark kernel provides several APIs for creating and manipulating these collections.
Spark SQL:
Spark SQL is a framework for working with structured data. This query system enables data through SQL as well as Apache Hyo, another type of SQL also called HQL, and supports data sources such as Hyo tables, Parquet data structures, CSV, and JSON.
In addition to providing a SQL UI for Spark, Spark SQL enables developers to combine SQL queries with data modification operations on RDDs supported in Python, Java, and Scala, and integrate SQL queries with complex analytics in one application…
This close coherence with the processing environment provided by Spark sets Spark SQL apart from other open-source data warehousing tools.
Spark Streaming:
The Spark Streaming data processing component is one of the components of Spark that provides data stream processing. Examples of data streams include log files created by web servers or a set of messages containing status updates sent by users of a web service or on social networks such as sending a post.
This component provides APIs for modifying data streams that are compatible with the APDs for RDDs in the Spark Core, which facilitates application development for developers and switches between applications that store data in main memory, on disk, or on time.
Real process, can be. In the development architecture of these APIs, to have fault tolerance, high productivity, and scalability, as in the Spark core component, attention has been paid to the points related to the development of distributed systems.
MLlib:
Spark has a library of machine learning (ML) APIs called MLlib. MLlib offers a variety of machine learning algorithms, including classification, regression analysis, clustering, and group refinement, and also supports features such as model evaluation and data entry.
MLlib also provides low-level machine learning structures such as descending gradient optimization algorithms. All of these methods are designed to run these programs at the Spark cluster level.
GraphX:
GraphX is a library for processing graphs and performing parallel processing on graph data. And GraphX, like the Spark Streaming and Spark SQL components, develops RDD APIs and enables us to create directional graphs by assigning specifications to each node and edge.
While GraphX also provides various operators for changing graphs (such as subgraph and map vertices) and a library of graph algorithms (such as PageRank and counting graph triangles).