









What solutions and techniques does Failover refer to in the network world?
One Of The Biggest Problems Faced By Network Equipment Is Failure. Almost All Network Hardware And Software Components Are Susceptible To Failure; therefore, Network Engineers Use Various Techniques Such As Redundancy And Failover To Overcome This Problem.
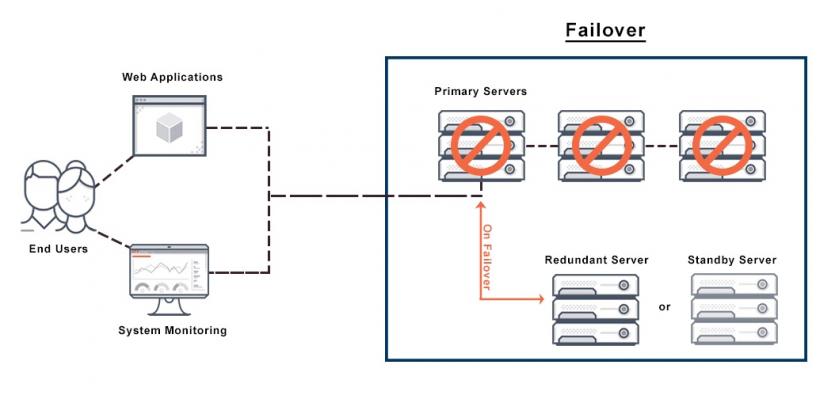
Failover refers to the ability to automatically and seamlessly switch to a reliable backup system to overcome a problem or malfunction of network components.
In such a situation, when a component or hardware fails, a standby system or a replacement component must enter the circuit and take over the workload of the failed component without the users noticing the problem.
This process should be done in the shortest possible time so that the delay of this transfer is not noticeable to the users.
Failover isFailoverly defined as a standby database, storage system, server, network infrastructure, communication links, or hardware components automatically coming online whenever a member or software stops working. To achieve the failover solution and achieve redundancy in the event of failure or abnormal operation of a system that is already in service, network engineers must have taken the necessary measures in advance. A subtle point that you should pay attention to is that all backup techniques, storage, or servers that play a vital role in an organization must be immune to failure because failover is one of the essential pillars of a disaster recovery plan.
What is Failover?
If we want a simple analogy, we should say that the automatic failover system in servers has the same function as heart rate monitoring systems. So that hardware and software tools are connected to servers to monitor their status permanently. However, if the secondary server detects a change in the state of the primary server due to a failure, it enters the circuit. It takes over the operations of the primary server. In this case, as long as the server’s performance is stable, the secondary server will be in standby mode.
Next, it alerts the network administrator or data center that the central server has a problem or needs to be brought online twice. Some systems are based on manual configuration, sending an alert to the data center administrator only when a problem is detected and then asking him to change the server status manually.
In the above architecture, the situation will be different if you use server or network virtualization technologies instead of physical servers. In the server or network virtualization process, host-based software is installed and run on a physical server and provides virtual servers in virtual machines to clients.
In the above architecture, the failover process can be done independently of the physical hardware components, such as servers, and the intelligent algorithms used by the software can manage and monitor the failure problem.
How does failover work?
The failover mechanism can be implemented as active-active, active-passive, or active-standby to reach the highest level of availability. Each of the above techniques implements the failover mechanism differently.
In the active-active mode, at least two nodes that actively run the same type of service simultaneously define an active-active cluster with high availability. The active-active cluster architecture works in a way that distributes workloads evenly across all nodes and does not allow a single node to receive more than the legal workload capacity.
This equal division, while improving performance, prevents one node from becoming too busy or another node from being idle at certain times. In this case, throughput and response time are improved as more nodes become available.
In active-passive cluster architecture, we need at least two nodes, but not all are in an active state. In a two-node system, when the first node becomes operational, the second node is placed in a passive state or standby mode as a failover server. In this case, if the activity of the central server stops, the second server, inactive or standby mode, comes into action.
However, if the primary server does not encounter a problem, the clients will receive the resources they need from the active server.
Similar to the active-active cluster mode, in the active-standby cluster architecture, both servers must have the same settings so that users will not notice the change if the server or other components, such as routers, enter failover mode. In an active-standby cluster, the standby node is always on. Still, its actual utilization is near zero, as it is only used if the primary server experiences a severe problem.
In an active-active cluster, the utilization rate of both nodes is 50-50. As mentioned, in the above architecture, each node alone can receive the entire load and manage it. The disadvantage of the above architecture is that if a node in the active-active architecture takes over more than half of the bag, in case of failure, the performance will decrease significantly because the other node has to perform the tasks of the other node while doing its work. also, do
The service delivery delay during a failure with an active-active configuration based on high availability is almost zero because both paths are active and the servers are constantly serving. If the above operation is done manually, this delay will increase. With an active-passive arrangement, the potential downtime may be prolonged, as the system must switch from one node to another, which takes time.
What is a failover cluster?
One of the essential topics that you should pay attention to when implementing failover mechanisms is ” Failover cluster. ” The above cluster is a set of servers that provide the three criteria of “Fault Tolerance,” “Continuous Availability,” or “High Availability.” A failover cluster-based network may use virtual machines, physical hardware, or both to overcome failures.
In such a situation, if one of the failover cluster servers fails, the network will automatically start the failover process. The advantage of the above method is that the process of directing the workloads of the disabled node to another node in the cluster is done in the shortest possible time so that there is no significant delay in providing services.
Typically, failover clusters are used with the goal of high availability or continuous availability, although most network engineers use failover clusters to achieve a fault tolerance threshold. Persistent availability clusters eliminate interruption when primary or secondary servers go down, allowing end users to continue to use applications and services without issue.
High-availability clusters indeed cause a short interruption in access to services. Still, on the other hand, they shorten the recovery time after a disaster thanks to automatic recovery and prevent data loss.
The recovery process in high-availability clusters can be managed using failover cluster management tools as part of failover cluster solutions. Are available and automated.
A cluster generally consists of two or more nodes or servers connected through network cables and software solutions. It is necessary to explain that other clustering technologies, such as parallel or concurrent processing, load Balan, citing hypermetrictric storage solutions, are used in some failover implementations.
In general, we must say that FFailoveris use to stabilize an Internet connection, relying on equipment redundancy in situations where failure may prevent access to equipment and services.
What is Application Server Failover?
Application servers are servers that run applications. Application servers have unique domain names and, ideally, should be implemented on a different servers; an efficient failover cluster typically is based on balancing solutions and application servers. In other words, an application server solution is a failover strategy to protect servers.
What is a failover? The failover over test checks the system’s capacity when the server fato is allocating enough resources at the time of recovery? This test determines whether the failover clusters case of the issues such as failures of servers, routers, storages, etc., do they have the necessary ability to manage additional resources and transfer operations to backup systems or not. The fault tolerance test examines the cluster’s ability to monitor and handle server problems.
The failover test is generally used to evaluate flexibility and security. For example, the above test evaluates the power of the system to manage and supply the required energy of an additional central processor or several servers after reaching a certain performance threshold. When a component fails, the fault tolerance threshold becomes unstable, which may cause other prob,lems such as data loss.
What are Failover and Failback?
In the world of computer networking, fFailoverrefers to transferring operations through a backup interface. For example, in the case of large data centers, a failover backup site is a complete data center consisting of a standby network and hardware equipment that is often located in a remote area from the leading site and is used when problems occur and during disaster recovery. In such centers, the failover solution includes tools or services to transfer operations to a new location.
Failback operation involves returning the condition to the initial state after maintenance. Typically, system designers implement failover n systems, servers, or networks that must have high reliability and guaran of high availability and continuous availability.
Thanks to virtualization solutions that reduce dependence on hardware, failover solutions ensure the continuity of business operations with little or no disruption to services.
last word
Data is the driving force of businesses; Hence, itessentialtant to have a robust disaster recovery strategy, especially at this point when threats from cyber-attacks and remote employees are increasing day by day.
primary main purpose of failover is to stop or reduce the failure of networks and systems. If the network infrastructure is configured correctly, failover and failback provides an integrated protection mechanism against most disruptions.