









What Is A Tree In A Data Structure And How Is It Navigated?
Tree Traversal Is One Of The Most Widely Used Algorithms In Various Software. A Tree Is A Data Structure Consisting Of Vertices And Edges That Are Hierarchically Related.
In tree traversal, there is an algorithm to access all vertices of the tree in an ordered manner.
What is a tree in a data structure?
A tree in a data structure is a set of vertices and edges in a hierarchical form, with each vertex except the root having a parent and one or more children. A tree in a data structure is a particular type of graph that consists of a root vertex and directed edges. The tree in the data structure can be represented as follows:
O
/ | \
o o o
/ \ |
o o o
In this tree, the primary vertex is the root, and other vertices are hierarchically below it. Each vertex can be connected to multiple children, but each child is attached to only one parent.
A tree is used in the data structure to solve various problems, such as searching, sorting, data transformation, etc. For example, a binary search tree is used for fast search in data sets, a dynamic tree for hierarchical representation of data and its changes, and a parse tree for analyzing and parsing textual data.
Tree navigation
In tree traversal, tree nodes are visited in a specific order. This navigation can be deep or superficial. In-depth traversal, a root vertex is first selected, then in-depth, each of the children of the current vertex is chosen as a new vertex, and the traversal continues to reach a sequence of vertices. In surface traversal, tree vertices are visited in order of different levels.
The tree level is used as a data structure in many computer software. For example, trees are used in binary search algorithms and finding optimal solutioptimaloptimization problems. Alsoproblemstraverathetheisthe used in graphics and game development software in software display graphic objects.
What are the types of tree navigation?
There are different types of tree navigation, the most important of which are as follows:
Depth-First Search
- Depth-First Search is one of the tree traversal methods in which a vertex is selected as the starting vertex and the, en fr each edge, all the children vertex children in this method, we first go to a vertex and then return to all the children of that vertex and so on until we reach a sequence of vertices.
- Tree traversal is divided into two types, recursive and stack-based. In the recursive method, the traversal is executed using the recursive function, and at each step, the children of the current vertex are visited in order. In the stack method, a stack is used to store the vertices, and at each step, the current vertex is placed on the stack, and then all its children are added to the stack in order.
According to the tree structure, a depth-first search may also be performed as a depth-first search with best-first. In this method, before visiting each vertex, a function is defined to evaluate its quality, and i. Intep, the vertex with the best evaluation is selected as the next vertex.
Depth-first tree traversal is used in many problems, such as depth-first search in node and first-page search problems.
Breadth-First Search
Breadth-First Search tree traversal is one of the tree traversal methods in which we first select the root, then visit the first children of all the vertices in the current level in order and then go to the next level. In other words, in this method, we first visit all the children of the starting vertex, then all their children, and so on.
Tree traversal is superficially divided into queue (queue-based) and double-ended (double-ended) types. In the queue method, a line is used to store vertices, and at each step, the current vertex is removed from the line, and all its children are added to the bar. In the bidirectional method, a bidirectional column is used to store the vertices, and in each step, the vertices on both sides of the line are visited in order.
Tree traversal is usually used for searching the shortest path between two vertices, finding the way with the least cost, graphical problems, and other similar problems. Also, depth and surface navigation may be needed in many issues to reach an optimal result.
Postorder Traversal
Postorder traversal is one of the tree traversal methods in which the traversal starts from the children of a vertex. We return to the current vertex, then go to the parent vertex, and then to another vertex to the left or right of the parent. In other words, in this method, all the children of a vertex are first visited, and then the vertex itself.
In postorder traversal, we first visit all the left children of the current vertex, then all its right children, and finally, we see the current vertex itself. This method is well suited for calculating the value of a tree statement, calculating the height of a tree, or calculating the depth of a tree.
Postorder traversal is one of the standard methods of tree traversal. It is used in many tree processing algorithms, such as the algorithm for calculating the value of a Boolean expression, the algorithm for calculating the depth of a tree vertex, and the algorithm for finding the number of leaves in a tree.
Preorder Traversal
Preorder traversal is one of the tree traversal methods in which the traversal starts from the root and then visits the left and right of a vertex. In other words, in this method, we first see the current vertex, then all its left children, and then all its right children.
More precisely, in preorder traversal, we first visit the current vertex, then l its left children, and then via its right children. This method works well for creating a copy of a tree, finding a tree path between two vertices, or creating a postfix expression from a tree.
Preorder traversal is one of the standard tree traversal methods. It is used in many tree processing algorithms, such as minimum spanning tree algorithm, binary search tree algorithm, and algorithm for calculating the value of a tree expression.
In-order Traversal
In-order traversal is one of the tree traversal methods in which the traversal visits the left children, the current vertex, and then the right children of a vertex in order. In other words, in this method, we first visit all the left children of the current vertex, then the vertex itself, and then all its right children.
In inter-order traversal, we first visit all the left children of the current vertex, then see the current vertex and all their right children. This method works well for sorting elements in a tree, creating an infix expression from a tree, or finding the value of the largest and smallest vertices in a tree.
Interorder traversal is one of the standard methods of traversing the tree. It is used in many tree processing algorithms, such as the binary search tree construction algorithm, the algorithm for calculating the value of a tree expression, and the algorithm for calculating the depth of a tree vertex.
What other tree traversal algorithms are there?
In addition to preorder traversal, mid-order traversal, and postorder traversal, there are other algorithms for tree traversal, which are generally divided into two categories: breadth-first traversal and depth-first traversal. Below are some of these algorithms:
- Level-Order Traversal: This algorithm starts from the root, and the vertices of each level are traversed in order, then the next level is addressed.
- Depth-First Search (DFS): In this algorithm, it starts from the root, and all the children of a vertex are scanned, then the next vertex is addressed until all the vertices are checked.
- Depth-First Traversal – Left First: This algorithm is similar to the DFS algorithm, except that the first left child of a vertex is traversed in each step.
- Depth-First Traversal – Right First: This algorithm is similar to the DFS algorithm, with the difference that the first right child of a vertex is traversed in each step.
- Double Preorder Traversal: In this algorithm, the left children of a vertex are traversed, then the vertex and all its right children are traversed.
- Double In-order Traversal: In this algorithm, the right children of a vertex are traversed, then the vertex itself and all its left children are traversed.
- Double postorder traversal: In this algorithm, the right children of a vertex are traversed, all their left children are crossed, and finally, the vertex itself is visited.
Other techniques, such as non-returning preorder traversal and non-returning interorder traversal, are used to traverse the tree using the stack. In these methods, a stack stores the vertices instead of callbacks. With this method, we get all the benefits of DFS algorithms but don’t need to use vector-length memory or queues.
In general, any algorithm used for tree traversal should be chosen based on the problem’s requirements and the characteristics of the tree.
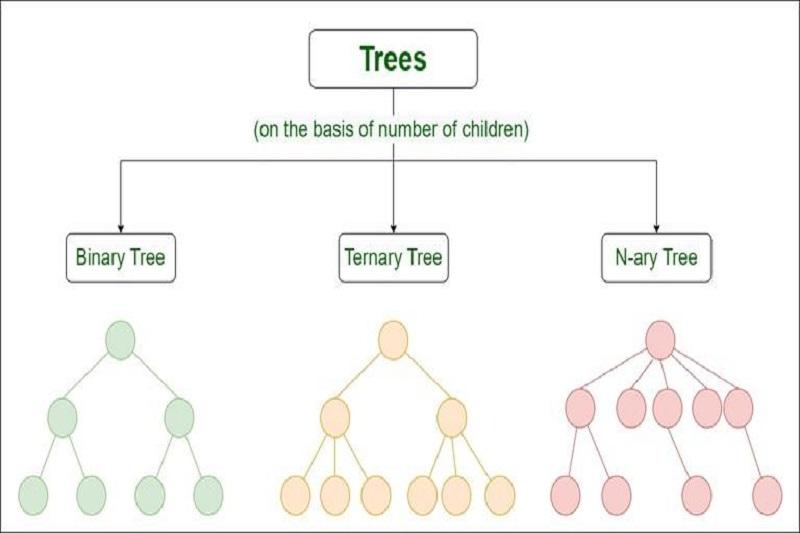
What is a generic tree?
A generic tree is a tree where each vertex can have more than one child. A generic tree is like a network of vertices; each vertex except the root can have several children.
In a generic tree, each vertex contains two parts: the data and a list of its children. For example, you can create a generic tree of characters in a book, with each character as a vertex and its children containing the characters that follow it.
The generic tree is used in many tree processing algorithms, such as tree traversal and tree height calculation algorithms. Also, the generic tree can be used to represent data structures such as XML and HTML.
What is the infinity tree?
An infinite or lambda tree is a particular tree with unlimited vertices and edges. In this tree, each vertex can be connected to an endless number of other vertices. An infinite tree can be represented as follows:
O
|
O
|
O
|
O
…
In this tree, each vertex has a single edge connected to its parent vertex, and no vertex has an advantage to the top of the tree. An infinite tree can be represented as an endless chain of vertices with unit edges.
Infinite trees are used in many scientific and industrial problems, including mathematics, physics, graph theory, programming, and artificial intelligence. For example, an endless tree can represent an infinite time series or continuous sensor data. Also, lambda trees can model dynamical systems such as neural networks and Boltzmann machines.
last word
Each method is suitable for use in different problems, and a combination of these methods may be required in some cases. In general, tree traversal is the most critical data structure algorithm used in many problems.