









What is a Canonical Tag ?
One of the most specialized and difficult SEO terms is a canonical tag or rel = canonical. Despite its complex title, the canonical tag is not a very strange subject and happens to be one of the most simple and practical SEO techniques. If you do not know what a Canonical Tag is, we suggest you stay with us until the end of this article.
In this article, while understanding the concept and application of canonical tags, we get acquainted with the power and effectiveness of SEO. We will also see in the following what problems will cause for the site SEO if not using it. After reading this article, you will learn well how to manage pages with different URLs and the same content and transfer the power of one or more pages to a reference page.
What is a Canonical Tag?
To begin, we first go to the definition of the canonical tag. The canonical tag (rel = canonical) is a piece of HTML code that we use to introduce the original version of pages that are almost duplicated and similar in content and the main keyword.
Imagine we have several pages with different URLs that are very similar content and the main keyword. In this case, Google tries to show the best version of these pages to users. To prevent the robots from making a mistake in choosing the original version, we use the canonical tag to introduce our original (suggested) version to Google.
How do Google bots detect canonical tags?
Canonical tags have a simple structure and are compatible. In a WordPress content management system, configuring the canonical tag is easy because the core of WordPress manages it well. But in the case of sites with proprietary coding, this tag with the following code is placed in the <head> section of the site:
<link rel = “canonical” href = “https://example.com/sample-page/” />
Google understands each part of this sample code as follows:
link rel = canonical: The link in this tag is the original (canonical) version of this page.
Href = https: //example.com/sample-page: The current version can be found at this URL.
How are pages created with duplicate content?
You may ask why this should happen? Or why should two or more pages with similar content be created on our site?
In response, we must say that no site is an exception to this rule, and for various reasons, duplicate content may be created on our site. Here are the most common reasons:
1. The page address changes depending on the type of application
A page of our site may have different URLs depending on the conditions of display and use. Designing a dedicated URL for the mobile version, using RSS on the site, and having a separate print version are examples of producing pages with the same content and similar URLs. Like the following example:
Main: https://bagheketab.com
Mobile: https://m.bagheketab.com
RSS: https://bagheketab.com/feed
Print: https://bagheketab.com/print
2. We receive several different URLs for a page from other sites
Sometimes due to incorrect links that we receive from other sites in the external linking process, a page of our site with several URLs is made available to Google. If a page does not have a canonical tag, it may be indexed by one of the same URLs in Google instead of the original URL. Because these URLs receive a lot of valuable links compared to the original version and are considered the main reference by Google.
3. We do not take URL management with HTTP and https seriously
All pages of our site can be accessed with https, HTTP, or www, but Google only selects one of them to display on the search screen. If we do not select the canonical tag correctly, these URLs will be difficult to manage. Because some pages will be indexed with www, others with https, and others with other modes.
4. When the main keyword of similar pages is selected
One of the most common problems with store sites is that there are very similar pages in terms of the main keyword but can not be placed on one page, Like the “Buy TV” page and the “TV price” page. The high similarity of the keywords of these two pages makes Google bots have trouble separating the two pages; one of them is not indexed or even cannibalized. For further reading, we suggest the article ” What is Cannibalization? ” » Read.
In addition to the above, other reasons lead to the production of pages with separate URLs and duplicate content. But the most important reasons were the ones we examined. In the next section, we want to talk about the importance of canonical tags in SEO and see why it is important to pay attention to this issue.
The importance of canonical tags in SEO; Control of strategic resources and budgets of the site
We all know that Google does not like duplicate content because it makes it harder for them to choose and does not know that:
- Which version of these pages will replicate the same and duplicate?
- Which version to rank for users related searches
- Or how to divide the rank of these pages between them
You might say that Google has become so powerful that it can finally find the original version of a page among the duplicates. But it is not just a matter of duplicate content; Having a canonical tag is essential in several ways to improve our site SEO, including:
1. Budget controls site crawl
The first blow to a site’s lack of canonical tags is a waste of the site’s creep budget. Because instead of discovering new and important content on our site, Google wastes its time crawling multiple copies of a page!
The truth about creep budgets is that they are limited to different sites. Creep budget is not something we control as a site administrator but is completely under the control of Google. But with the proper use of the Canonical tag, we can have limited control over the creep budget. Do we suggest you read the article What is Creep Budget?
Canonical tag prevents duplicate pages from crawling!
A creep budget is very important for sites, Especially large sites with a large number of pages. So we can use the canonical tag to make sure that Google bots process our new pages and content instead of crawling different versions of mobile, print, and one page. We need to choose the canonical page correctly. This speeds up the indexing of updated content and even increases the chances of reviewing and indexing new articles.
Do not forget one important point!
Google says it usually respects the canonical address we choose, But not always! Because in the end, it is Google that chooses the home page or the so-called canonical based on its instructions.
2. Facilitates the process of ranking pages with similar content
If we do not use the Canonical tag, in the best case, Google will select and rank its desired page as the main page, and other pages will not be indexed, or if they are indexed, they will not be ranked properly. But this is not always the case!
If we introduce the main page to Google with the canonical tag, the validity of other duplicate pages and the validity of all internal and external links given to these pages will be transferred to the main page or reference. This facilitates the process of ranking the reference page and pages with duplicate content and prevents duplicate pages from being ranked.
The canonical tag prevents duplicate page rankings
To avoid duplicate pages and ensure that the main content or reference content is the same content ranked by Google and displayed to users, we must use the canonical tag to integrate the ranking signals of these pages.
3. Reduces the possibility of cannibalization of similar pages
The next use of the canonical tag is to prevent competition between pages with similar content on the SERP results page. When we specify a canonical address for several similar pages, the validity of these pages and the validity of the external links associated with them are transferred to the canonical page and prevent homosexuality on these pages.
Suppose we have several different pages in which we talk about teaching white hat SEO techniques. Setting the canonical URL allows Google to understand which page we want to show users in the SERP results and, to put it better, which page to rank; This is one of the most important uses of canonical tags.
4. The Canonical tag prevents periodic changes to the reference version or the home page
If we do not use the canonical tag to specify the home page or reference, over time, by updating the content of this page or other pages that have been canonized to this page and also changing the external link building program of these pages, Google at its discretion the reference page And displays another URL in the search results.
In such cases, that page may lose its status. The statistical information recorded in the Google Console search, Google Analytics, or any other analytics tool may be changed and virtually unanalyzed. The next section will learn how to use the canonical tag to prevent such issues.
Get acquainted (gain, obtain) with present-day techniques that came from Canonical Tag Implementation
Implementing the Canonical tag is not a difficult task, and it does not matter which method you use to run it. But there are five golden rules that you should always remember when choosing a canonical tag.
Rule 1: Use full URLs
“You can use any method, but I recommend using full URLs to ensure they are interpreted correctly,” John Müller (Google Webmaster Analysis Director) tweeted in October 2018.
So according to John Müller, we should instead have this URL structure:
> link rel = “canonical” href = ” / sample-page /” / >
Use the following structure:
> link rel = “canonical” href = “ https://example.com/sample-page /” />
Rule 2: Put lowercase URLs in the canonical tag
Since Google may treat uppercase and lowercase URLs as two different URLs, first make sure that uppercase URLs are applied to the server, then use them for the canonical tag of the page.
Rule 3: Use the correct version of the domain (HTTPS instead of HTTP)
If you have modified the site SSL, make sure that none of the site’s current tags use the old SSL, HTTP. Doing so could theoretically confuse Google bots. For example, if the current canonical of our site has the following structure:
> link rel = ”canonical” href = ” HTTP : //example.com/sample-page/” />
Let’s change it like this:
> link rel = ”canonical” href = ” https : //example.com/sample-page/” />
Of course, if your site’s SSL has changed from HTTPS to HTTP, you should do the opposite.
Rule 4: Use the self-referential canonical tag
“I recommend using my canonical referral tag because it tells us which page you want to index or the URL of the page should be when indexed,” says John Mueller. “Even if you only have one page, sometimes the URL of the same page is subject to various changes, all of which can be cleared with a canonical rel-tag.”
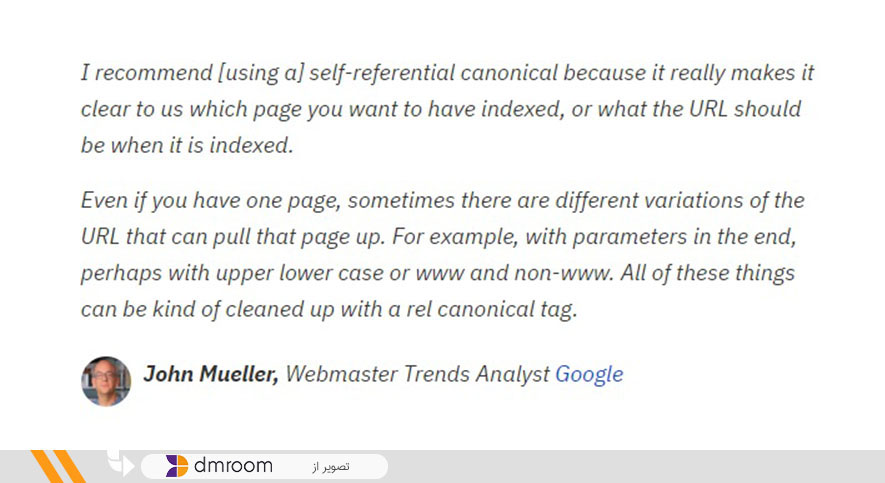
A canonical self-referencing tag is an address that refers exactly to itself. For example, if https://example.com/sample-page is the page address we want, the canonical tag that references that page would look like this:
> link rel = ”canonical” href = ” https://example.com/sample-page /” />
In popular cms like WordPress, this is done automatically. But in the case of dedicated cms, you should ask your developer to design this code.
Rule 5: Put only one canonical tag for each page
Each page must have a canonical tag. If you select more than one canonical tag, Google will ignore both. Of course, in WordPress, it is not possible to import more than one tag by default. But in the case of proprietary CMSs, in the case of multiple rel = canonical notifications, Google is likely to ignore them all.
How to check if Google accepts canonical tags
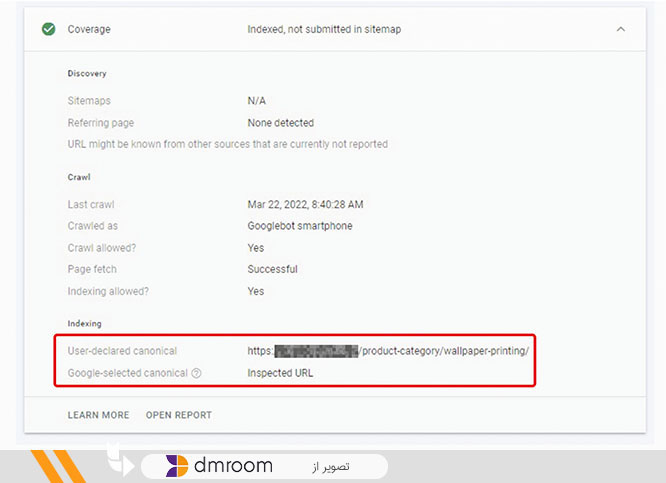
As important as it is to use the canonical tag correctly, it is important to ensure that the canonical tag we choose for a page is accepted. Checking the canonical tags of pages is easy. We need to enter the Google console search and enter the desired page address in the URL inspection section to get started. After a few seconds, Google will show us a page similar to the one below, which contains information about the crawl and index of that page.
We have two options at the bottom of this page: User canonical and Google canonical. If the canonical user and the canonical Google are the same, Google has accepted the URL that we have introduced as the canonical. But if these two URLs were different, Google has not have accepted our Canonical, and the page recognized as the original version of the content is considered Canonical!
Frequently Asked Questions
Can we use the canonical tag to solve the Duplicate content problem?
Yes. When we want to restrict Google access to two similar or Duplicate content, instead of No-Indexing them, we should use the Canonical tag to link one of the two contents to the other content.
What is the best plugin for canonical tag settings on WordPress sites?
The most popular plugins, in this case, are Yoast and RankMath.
What is the difference between using a canonical tag and a 301 redirect?
In Redirect 301, in addition to transferring the credentials of a page to the landing page, we will no longer have access to the old or redirected URL. But this is not the case with the canonical tag, and we still have access to the URLs of duplicate content pages. We suggest you read the article What is a 301 redirect for more information.
Concluding remarks
In this article, we explored what a Canonical Tag is and its uses. We also learned that canonical tags are not very complicated and only involve us a little at first.
The canonical tag does not have specific instructions for Google, and Google bots can discard our canonical tag of their choice at their discretion. But we still recommend that you take this important signal to search engines seriously and specify a canonical page URL for each page. If you have any questions or experiences about the canonical tag, how to configure it, or canonical tag applications, we’d love to hear from you in the comments section. We will answer you in the shortest time.