

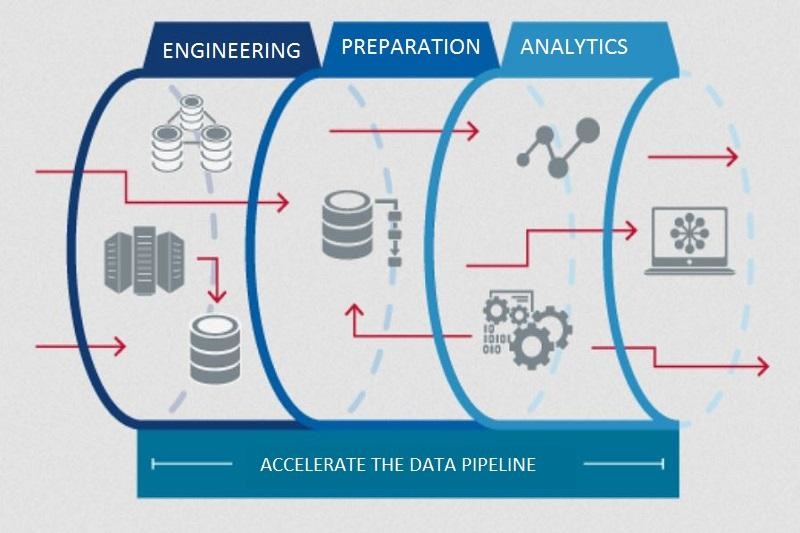
Data Pipeline Is A Set Of Processes That Are Used To Collect, Transform, Analyze, And Transfer Data So That They Can Be Used In A Suitable Format For Various Applications.
Typically, tools and processes are used to build these data transmission lines that automatically transfer data from one stage to another at each data collection and processing stage.
Data is usually collected from various sources such as databases, files, web services, and others in a Data Pipeline. Then, these data are automatically processed in multiple steps, such as transformation, analysis, cleaning, and data synthesis.
Finally, the data is transferred to the target system for use in applications and other existing methods. Using Data Pipelines in organizations can improve the efficiency and accuracy of data collection and processing and help reduce the time and cost required for data processing.
What kind of tools are there to implement Data Pipeline?
To implement a Data Pipeline, various tools, and processes help you get the most out of your data. Some of these tools are:
- Apache NiFi is an open-source tool for creating and managing data pipelines. This tool allows controlling and tracking data through a simple graphical user interface.
- Apache Kafka is a distributed messaging system for transferring data and events between systems. This tool allows high-speed data delivery and high reliability.
- Apache Spark is a distributed framework for big data processing. This tool provides real-time and batch data processing and support for different data types.
- AWS Data Pipeline: A Data Pipeline management service for Amazon Web Services. This service allows creating and managing Data Pipelines for transferring and processing data in the AWS environment.
- Microsoft Azure Data Factory is a Data Pipeline management service in the Microsoft Azure environment. This service allows building, managing, and implementing Data Pipelines to transfer and process data in Azure.
- Google Cloud Dataflow: is a distributed data processing service for use in Google Cloud. This service allows Real-Time and Batch data processing and support for different data types.
Additionally, there are tools like Apache Airflow, Talend, StreamSets, and Pentaho as Data Pipeline management tools. Each of these tools has different features and capabilities that you can use depending on the needs and conditions of the project.
How to optimize data transmission lines?
You can use different approaches to optimize data transmission lines and get better performance. Below I mention some essential strategies to optimize data transmission lines:
- Requirements analysis: To optimize data transmission lines, you must first carefully analyze the requirements related to data processing. Requirements analysis helps you find the best solution for data processing and generally improves the performance of data transmission lines.
- Resource management: Resource management includes hardware and software resources. To optimize data transmission lines, you must use appropriate hardware and software resources to quickly and effectively process data.
- Optimization of algorithms: Data processing algorithms should be optimized in such a way as to increase the speed of data processing and reduce the problems related to the large volume of data.
- Use real-time technologies: If the data processing is used for real-time applications, you should use real-time technologies such as Apache Kafka and Apache Spark Streaming to perform real-time data analysis.
- Maintenance and updating of data transmission lines: To optimize data transmission lines, you must keep the information storage resources up to date and perform troubleshooting using various methods such as monitoring, reports, and similar tools to identify any problems and improve the performance of data transmission lines. slow
- Use cloud-based solutions: Cloud-based solutions such as AWS Data Pipeline, Azure Data Factory, and Google Cloud Dataflow can help you improve data pipeline performance, reduce hardware costs, and increase stability.
Optimizing data transmission lines requires a detailed analysis of requirements, resource management, optimization of algorithms, and various methods to maintain and update data transmission lines.
Are data transmission lines suitable for all organizations?
Data transmission lines are essential for most organizations, but their suitability depends on the specific needs of each organization. Data transmission lines are critical for organizations that deal with large volumes of data. More specifically, large technology companies, banking companies, insurance companies, transportation companies, etc., need data transmission lines.
Using data pipelines, organizations can process data in a centralized and managed environment, in real-time or in batches, and use it for accurate analysis and better decision-making. Also, by using data transmission lines, you can reduce data processing costs and improve the performance of your system.
Although data transmission lines are essential for improving the business activities of many organizations, small and medium-sized organizations should be aware that implementing data transmission lines may incur hardware and software costs, development and maintenance costs, etc. Therefore, using other solutions instead of data transmission lines in this situation may be helpful.
How to create a data pipeline?
The process of building data transmission lines requires going through various stages, the most important of which are the following:
- Requirements Analysis: To create data transmission lines, you must carefully analyze the data processing requirements. This includes defining required resources, data processing processes, used algorithms, etc.
- Determining hardware resources: After analyzing the requirements, you must evaluate the hardware resources needed for data processing. This includes choosing the number of servers, processors, memory, disks, etc.
- Selection of required tools: To create data transmission lines, you must use various devices such as Apache Kafka, Apache Spark, Hadoop, Apache NiFi, etc. To choose the best tools, you need to consider data processing processes, data volume, and other constraints.
- Design and implementation of data transmission lines: After determining the requirements, hardware resources, and required tools, you should start designing and implementing data transmission lines. You should identify and implement data processing steps, communication between different services, and data structures at this stage.
- Test and evaluation: After implementing the data transmission lines, you must test and evaluate them. It would be best to ensure that the data processing processes are done correctly and that the output data is correct and efficient.
- Maintenance and improvement: After setting up the data transmission lines, you must maintain and improve them and identify and fix problems through continuous evaluation.
In general, creating data transmission lines requires a detailed analysis of requirements, determination of hardware resources, selection of appropriate tools, implementation and testing, and continuous improvement.
Suitable programming languages for building data transmission lines
You can use different programming languages to implement data transmission lines. In the following, we mention some languages that are suitable for implementing data transmission lines:
- Python: Python is one of the most popular programming languages, ideal for implementing data transmission lines. Python has several data processing and analysis libraries, including Pandas, NumPy, SciPy, Scikit-learn, and TensorFlow.
- Java; Java is a powerful programming language that is suitable for implementing data transmission lines. Apache Hadoop and Apache Spark are projects that use Java to implement data pipelines.
- Scala: Scala is a new programming language for implementing data transmission lines. Apache Spark is among the projects implemented using Scala.
- SQL is a query language used to process data in databases. SQL has capabilities for large and distributed data processing.
- Go is a fast and reliable programming language for implementing data transmission lines. The Go language has capabilities for processing extensive data.