


Different Companies, Websites, And Prominent Job Sites Have Described The Job Title Of Data Scientist As One Of The Most Attractive Jobs Of The 21st Century.
For example, Harvard Business Review named data scientist the hottest job of the 21st century, while job site Glassdoor listed it as one of the top 25 jobs in the United States.
In 2017, IBM predicted that the demand for data science professionals would increase by 28% by 2022. It’s no wonder that in the age of big data and machine learning, data scientists are becoming the rising stars of the IT world.
Statistics clearly show that companies that can use data to improve how they serve customers, build efficient products, and improve their business operations will have better economic progress than their competitors.
To become a data scientist, you must prepare to impress future employers with your knowledge.
To do this, you must be able to impress them in job interviews by relying on your knowledge and skills.
Accordingly, in this article, we have collected some frequently asked questions of data science specialist recruitment tests so that you can prepare before attending the interview.
What is data science?
Data science combines statistics, mathematics, specialized programs, artificial intelligence, machine learning, etc. Data science involves using specific principles and analytical techniques to extract information from raw data anning, decision-making, etc. In simpler terms, data science means analyzing data to gain actionable insights. With this introduction, we will go to the most popular data scientist recruitment questions you are expected to face in recruitment meetings. Answers are also compiled to help readers.
1. What is the difference between supervised and unsupervised learning?
Supervised learning uses known and labeled data as input based on a feedback mechanism. Standard supervised learning algorithms include decision trees, logistic regression, and support vector machines. In contrast, unsupervised learning uses unlabeled data as input and lacks a feedback mechanism. Among the standard unsupervised learning algorithms, k-means clustering, hierarchical clustering, and Apriori Algorithm should be mentioned.
2. How is logistic regression performed?
Logistic regression measures the relationship between the dependent variable (the label of what we are trying to predict) and one or more independent variables (the characteristics we are interested in) by estimating the probability using its underlying logistic function (sigmoid). Figure 1 shows how logistic regression works.
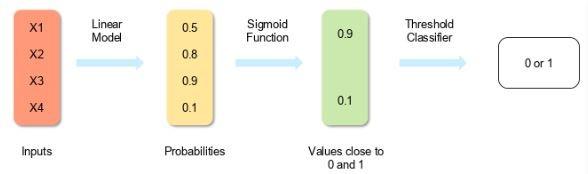

figure 1
The formula and graph of the sigmoid function are shown in Figure 2.
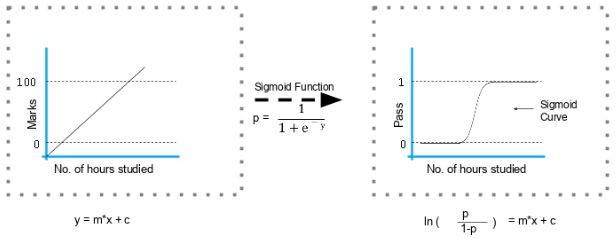

figure 2
3. Explain the decision tree construction steps
- Consider the entire data set as input.
- Calculate the entropy of the target variable and the predictive features.
- Use the Information Gain technique to calculate all features.
- Select the feature with the highest information as the root node.
- Repeat the same procedure in each branch until the decision node of each unit is finalized.
For example, suppose you want to build a decision tree to decide whether to accept or decline a job offer. The decision tree of this problem is similar to Figure 3. The decision tree indicates that a job offer should be taken if the salary is more significant than $50,000, the commute is less than one hour, and incentives are offered.

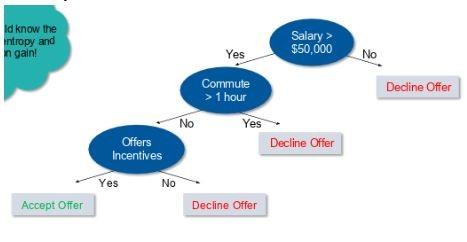
Figure 3
4. How to build a random forest model?
A random forest consists of several decision trees. If you divide the data into different packages and build a decision tree in each data group, the random forest will put all those trees next to each other. The steps to create a random forest are as follows:
- Randomly select k features from the set of m features such that k << m.
- Among the k features, compute node D using the best split point.
- Split the node into forkable nodes using the best splitting mechanism.
- Repeat steps 2 and 3 to complete the leaf nodes.
- Construct a forest by repeating steps 1 to 4 n times for n trees.
5. How can you avoid overfitting your model?
Overfitting refers to a model that only fits a minimal amount of data and ignores the larger perspective of the data. There are three main ways to avoid the problem of overfitting a model.
- Keep the model simple. Consider fewer variables to remove some of the noise in the training data.
- Use cross-validation techniques, such as k folds cross-validation.
- Use regularization techniques such as LASSO, which remove model parameters if there are too many fitting probabilities.
6. What is the difference between univariate, bivariate, and multivariate analysis?
Univariate data contains only one variable. The univariate analysis aims to describe data and find patterns in them. A typical example in this context is the height of students. For univariate data, patterns can be studied by inferring and looking at mean, median, mode, dispersion or range, minimum, maximum, etc.
Bivariate data includes two different variables. This type of data analysis deals with causes and relationships, so the research is done to determine the relationship between two variables. A typical example in this field is the combined effect of increasing temperature on energy consumption. Here, temperature and increased energy consumption are directly proportional to each other. The higher the temperature, the higher the energy consumption. Multivariate data consists of three or more variables categorized under multivariate subcategories. Multivariate data are similar to bivariate data but include more than one dependent variable. A typical example in this field is the house, where the number of rooms, storage, area, and several floors affect its price. To identify patterns in these variables, you can use average, median, mode, dispersion or range, minimum, maximum, etc. For example, you can start describing the data and use it to guess the price of a house.
7. What methods are there to select attributes for variables?
There are two main methods for feature selection, which are called filter and wrapper methods. Among the filter methods, linear discriminant analysis, ANOVA, and Chi-Square should be mentioned. Among the covering methods, the following should be noted:
- Forward selection: We test one feature at a time and gradually add other features until we reach the desired fit.
- Backward selection: We test all the features, and after testing, we remove them one by one to see which ones perform better.
- Remove recursive features: Recursively, we check all the different features and how they pair together.
Generally, Wrapper methods are more important. Of course, if a lot of data analysis is to be done with the wrapper method, powerful hardware is needed.
8. Using a programming language you are familiar with, write a program that prints the numbers from one to 50, but for a multiple of three, instead of the number, the program prints the word Fizz, and for a multiple of five, Buzz. Print FizzBuzz for numbers that are multiples of three and five.
The code shown in Figure 4 shows how to do this. Note that the specified range is 51, which means 0 to 50. When working with arrays and data structures, pay attention to the point that the spatial index starts from 0, not 1.


Figure 4
9. You are given a dataset that consists of variables that have more than 30% missing values. How do you work with such a collection?
Data scientists use the following methods to manage missing data amounts:
- We can delete rows with missing data values if the data set is large. This is the fastest way. Next, we use the remaining data to predict the values.
- For smaller datasets, we can replace missing values with the mean of the data using data frames in Pandas.
10. How do you calculate Euclidean distance in Python for given points?
plot1 = [1,3]
plot2 = [2,5]
Euclidean distance can be calculated as follows:
euclidean_distance = sqrt( (plot1[0]-plot2[0])**2 + (plot1[1]-plot2[1])**2 )
11. What is dimension reduction, and what are its advantages?
Dimensionality reduction refers to converting a data set with large dimensions to data with smaller sizes (fields) to transmit less of the same information. This reduction helps to compress data and reduce storage space. Also, it reduces the computation time because the dimensions require less computation. In addition, dimensionality reduction plays a vital role in lowering redundant features.
12. How do you calculate the eigenvalues and eigenvectors of the following 3×3 matrix?
| 2 | -4 | -2 |
| 2 | 1 | -2 |
| 5 | 2 | 4 |
The desired equation, along with the mechanism for determining the expander, is as follows:
(-2 – λ) [(1-λ) (5-λ)-2×2] + 4[(-2) x (5-λ) -4×2] + 2[(-2) x 2-4(1- λ)] =0
– λ3 + 4λ2 + 27λ – 90 = 0,
λ3 – 4 λ2 -27 λ + 90 = 0
Here we have an algebraic equation made of eigenvectors. The process of insertion and multiplication is as follows:
33 – 4 x 32 – 27 x 3 +90 = 0
Therefore, (λ – 3) is a factor:
λ3 – 4 λ2 – 27 λ +90 = (λ – 3) (λ2 – λ – 30)
The eigenvalues are 3, -5, and 6:
(λ – 3) (λ2 – λ – 30) = (λ – 3) (λ+5) (λ-6),
Now we calculate the eigenvector for λ = 3:
For X = 1,
-5 – 4Y + 2Z =0,
-2 – 2Y + 2Z =0
Subtraction of two equations:
3 + 2Y = 0,
Subtract again to the second equation:
Y = -(3/2)
Z = -(1/2)
Similarly, we can calculate the eigenvectors for -5 and -6.
13. How should we maintain the established model?
The steps to maintain the established model are as follows:
- Monitoring: Continuous monitoring of all models is required to determine the accuracy of their performance. When you change something, you want to see how your change will affect other factors. This process should be done under supervision to make sure things are done correctly, and the desired result is achieved.
- Evaluation: Evaluation criteria determine whether a new algorithm is needed.
- Comparison: New models are compared to determine which model performs best.
- Reconstruction: The best model is tested based on current and new data to determine its performance.
14. What are recommender systems?
A recommender system predicts how users rate a particular product based on their interests. Recommender systems can be divided into two main groups:
Collaborative filter
For example, Last. FM recommends songs that users with similar interests are listening to. Amazon also uses a similar pattern when offering products. Some sales sites show the message “Users who bought this product, etc.” when users visit products.
Content-based filtering
Pandora uses a song’s characteristics to recommend pieces with similar features. Here, we look at the content instead of who listened to the music.
15. How to find RMSE and MSE in a linear regression model?
RMSE and MSE are two of the most common accuracy measures for a linear regression model. RMSE shows the Root Mean Square Error.
r> rmse
[1] 3.339665e-11
MSE shows the mean square error (Figure 5).


Figure 5
16. How do you choose k for k-means?
We use the elbow method to select k in k-means clustering. We are using the elbow method to perform k-means clustering on the dataset. Here, k represents the number of clusters. k in the sum of squares (WSS) is defined as the sum of the squared distance between each cluster member and its center.
17. How to solve the problem of outliers?
You can remove outliers only if the values are useless. If removing outliers is difficult, try the following first.
Try a different model. Non-linear models can fit data identified as outliers by linear models. So, make sure you choose a suitable model.
Try to normalize the data. This way, the data points will point to a specific range.
You can use algorithms that are less affected by outliers. An excellent example of this is random forests.
18. How can you calculate accuracy using a confusion matrix?
Imagine the confusion matrix of Figure 6. The accuracy calculation formula is as follows:
Accuracy = (true positive + true negative) / total observations
Accuracy = (True Positive + True Negative) / Total Observations
= (262 + 347) / 650
= 609 / 650
= 0.93
In the example above, the accuracy is 93%.

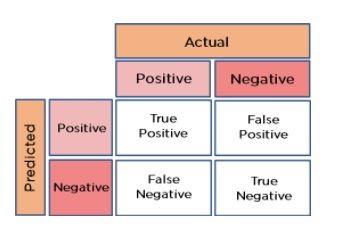
Figure 6
19. Write an equation and calculate the accuracy and recall rate.
Consider the same confusion matrix as in the previous question (Figure 7).
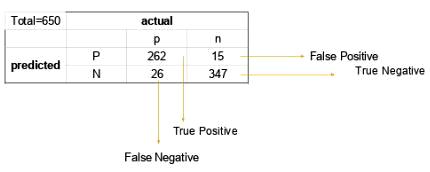

Figure 7
Precision = (True positive) / (True Positive + False Positive)
Accuracy = (true positive) / (true positive + false positive)
=262 / 277
=0.94
Recall Rate = (True Positive) / (Total Positive + False Negative)
Call rate = (true positive) / (total positive + false negative)
=262 / 288
=0.90
20. The recommendations seen on Amazon are the result of which algorithm?
Recommender engine based on collaborative filtering. This engine makes predictions about what someone else might be interested in based on other users’ interests. Collaborative filtering explains the behavior of other users and their purchase history in terms of ratings, choices, etc.
In this algorithm, the characteristics of an element are unknown. For example, a sales page shows that a certain number of people buy a new phone and a screen protector simultaneously. The next time someone buys a phone, the user may be recommended to purchase a protective glass.
21. Write a basic SQL query that lists all orders with customer information
Typically, we have ORDER tables and CUSTOMER tables that contain the following columns:
- Order Table
- Order number (Ordered)
- Customer ID (Customer)
- Order Number (OrderNumber)
- total amount (total amount)
- Customer Table
- Id
- first name
- LastName
- City
- Country
The SQL query based on the above columns is as follows:
SELECT OrderNumber, TotalAmount, FirstName, LastName, City, Country
FROM Order
JOIN Customer
ON Order.CustomerId = Customer. Id
22. You are given a dataset about a cancer diagnosis. You have built a classification model and achieved 96% accuracy. What method do you suggest to evaluate its performance?
Early detection is crucial in cases like cancer and can significantly improve the patient’s prognosis. In matters related to diagnosis, we face a big problem called data imbalance. In an imbalanced data set, accuracy should be considered a performance measure, and thus we should focus on the remaining four percent that may indicate misdiagnosis. Therefore, to evaluate the model’s performance, we must use the sensitivity criterion for the actual positive rate, the specificity for the real negative rate, and the F criterion to determine the classifier’s performance.
23. Which of the following machine learning algorithms can be used to impute missing values for categorical and continuous variables?
- K-means clustering
- Linear regression
- K-NN (k-nearest neighbor)
- Decision trees
We can use the K-nearest neighbor algorithm because it can calculate the nearest neighbor distance, and if it does not have a value, it will calculate the closest neighbor distance based on other features.