


Statistics Show That In 2021 And 2022, Jobs In The Field Of Data Science Have Had An Exponential Trend.
Interestingly, jobs related to data engineering are one step ahead of other data-oriented jobs.
Typically, people who want to enter the world of data engineering need a particular set of skills; however, to succeed in this field, apart from the traditional abilities, other skill sets are required that we will explore in this article.
What are the 11 essential skills of a data engineer in 2023?
Amid the Corona epidemic, we saw a massive growth of information stored on cloud infrastructure. So clou,d service providers were forced to review strategies, information storage services, security protocols, and communication channels. One of the reasons for this is organizations’ interest in multi-cloud environments; Gartner predicts that more than 85% of organizations will use cloud infrastructure extensively by 2025. In 2023, the number of jobs related to data science will grow significantly, but two job titles, data engineering and MLOp will receive more attention than others.
Research conducted by various institutions shows that besides the traditional skills he needs, a data engineer should think about learning to work with new technologies and interact with different sources of information storage and cloud infrastructure. With this introduction, let’s move on to the skills and requirements that a data engineer will need in 2023.
11. Scriptwriting
Yes, a data engineer should be proficient in scripting. Linux, Bash, PowerShell, TypeScript, JavaScript, and Python are essential skills that a data engineer should have in 2023. In addition, it should be able to work with data-oriented and text-oriented technologies such as CSV, TSV, JSON, Avro, Parquet, XML, ORC, etc. Data engineers should have a high level of skill in ETL/ELT tools and related techniques to design and build the data transmission line.
10. Programming
Last year, Python, Java, C#, and C++ were the main programming languages in mechanical engineering, but this trend is expected to change in 2023. So that Go, Ruby, Rust, and Scala programming languages are among the popular programming languages in this field. Powerful languages can work with technologies like Apache Spark and cloud infrastructures like Amazon Glue and DataBricks. In the coming years, working with real-time data streams generated in social networks, natural language processing, e-mail, and cloud-based services and systems will also receive attention.
9. DevOps
One of the essential skills you should consider learning as a data engineer is DoApps. This domain includes Software Development Life Cycle (SDLC), Continuous Development (CD), and Continuous Integration (CI), along with techniques and tools such as Jenkins, Git, and GitLab. These applied skills, along with DataOps and Data Governance, enable producing high-quality data that leads to more accurate results.
8. SQL
A data engineer needs to prepare the schema and work based on it to perform his duties properly. It is good to know that cloud-based systems have implemented better SQL support through APIs so that engineers can write their queries more precisely. Relational database management systems (RDBMS) continue to play an essential role in data storage, so learning how to work with these systems should not be neglected.
7. NoSQL
Unfortunately, some experts and even organizations point out that Hadoop is no longer a critical technology as we move to the cloud. The cloud contains unstructured or semi-structured (no SQL schema) data. Indeed, NoSQL, whether based on open-source Apache, MongoDB, Cassandra, or otherwise, requires a platform capable of handling large volumes of unstructured data.
As a data engineer, you should know enough about manipulating key-value pairs and objects like JSON, Avro, or Parquet. Hence, you should have sufficient knowledge about the technologies based on NoSQL.
6. The ability to accurately construct data transmission lines
Data Lakes is one of the essential terms of the data-oriented world, which is associated with various and sometimes new technologies such as DataBricks Lakehouse and Snowflakes Data Cloud. Working with real-time data streams and running dialogs on data warehouses, JSON, CSV, and raw data is a daily task of a data engineer. How and where engineers store data matters a lot. Hence, you must know the available data engineering (ETL/ELT) skill sets and tools.
5. Hyper Automation
Data engineers have specific tasks, but other tasks, such as scheduling and executing tasks and tracking events, are also assigned. To perform these tasks, these professionals must be able to work with tools such as Scripting and Data Pipelines. Typically, a data engineer does not have enough time to do specific tasks and has to turn to automation tools. Gartner says: “Successful data science teams are not neglecting the cloud and automation. These two powerful solutions help them improve the quality of work, accelerate business processes and make key decisions more quickly.”
4. Illustration
Exploratory Data Analysis (EDA) has now become one of the critical tasks of data engineers. The above solution helps data engineers to explain complex and technical information in simple language. For this reason, a data engineer should be able to work with tools such as SSRS, Excel, PowerBI, Tableau, Google Looker, and Azure Synapse.
3. Machine learning and artificial intelligence
A data engineer should have basic knowledge of artificial intelligence, machine learning terms, and algorithms. More specifically, at least familiar with Python libraries such as Pandas, NumPy, and SciPy. Tools available through the Jupyter Notebook Integrated Development Environment. With this description, you should not only know how to work with these tools, but you should also have sufficient knowledge of Jupiter Notebook. In addition, it is better to know how to work with cloud-based tools such as AWS Sagemaker, Microsoft HDInsight, or Google’s DataLab toolset to work better with complex data sets.
2. Multi-cloud computing
Multi-cloud environments have become widespread, and almost all large companies and organizations use multi-cloud combinations to perform daily tasks. More specifically, companies that don’t want to give all their data to cloud service providers prefer multi-cloud. Statistics show that almost 76% of companies use public and private clouds to use the advantages of both environments in the best way. Based on this definition, we must say that as a data engineer, you must understand the essential technologies that makeup cloud computing. Hence, increase your knowledge of implementing IaaS, PaaS, and SaaS.
1. Familiarity with topics related to the analysis of graphs
Numerical data analysis is done to gain detailed insights and solve problems. The study analyzes relationships between entities tend of numerical data. Graph algorithms and graph databases and their research are used in social network analysis, fraud detection, supply chain performance identification, and search engine optimization.
To understand the subject of graph analysis, we must first know what a graph is. A chart is a mathematical term that shows relationships between entities.
There are different types of graphs, as follows:
- Directed graphs: All edges are produced from one node to another. These types of charts show asymmetric relationships between nodes. This type of Graph is called a directed network.
- Undirected graphs: All edges connect one node to another, but the relationship’s direction is unclear. Figure 1 shows the difference between these two nodes. This Graph is called an undirected network. Undirected graphs show symmetric relationships.
- Weight graphs: A weighted graph has edges that define their weights. These weights show the shortest path.
- Cyclic graphs: shows a route from at least one node to the same node.
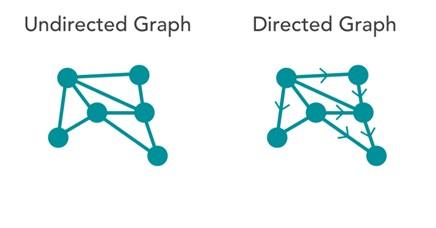

figure 1
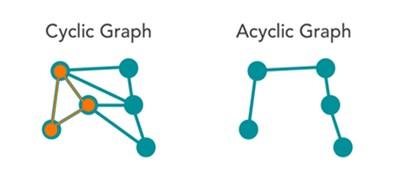

figure 2
Figure 2 shows the above graphs. One of the essential skills that a data engineer must have is the ability to analyze charts, also called network analysis; These analyzes are used to show relationships between entities such as customers, products, information, etc. Organizations use graph models to gain insights that can be used in marketing or social media. It’s good to know that preparing and analyzing graphs is one of the most profitable jobs an engineer or data analyst can do.
Different types of graph analysis
There are different methods for analyzing graphs and graph algorithms. Data engineers use the following methods to analyze charts:
- Centrality analysis: This analysis determines the importance of a node in a graph network’s connections and helps estimate the most influential people in a social network or web page using the PageRank algorithm. Figure 3 shows the general scheme of centrality analysis.


Figure 3
- Community detection: From the distance and density of relationships between nodes, it is possible to find groups of nodes that regularly interact with each other in a network. The associative analysis is related to patterns of behavior detection in communities. Figure 4 shows the overview of the above comment.


Figure 4
- Connectivity analysis: Determines how strongly or weakly two nodes are connected. In summary, the more the direct and indirect edges of two nodes, the greater the connection between two nodes.
- Path analysis: examines the relationships between nodes. This analysis is mainly used in the field of identifying the shortest distance.
- Link Prediction: By calculating nodes’ neighborhood and structural form, it estimates new relationships or existing connections not specified on the Graph. Figure 5 shows an overview of link prediction analysis.
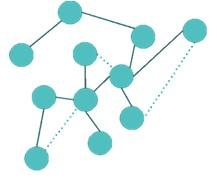

Figure 5
Graph analysis plays a vital role in identifying patterns. One of the main applications of graph analysis is related to recommender systems. You’ve probably encountered “people you might know” or “songs you might like” on social media. These recommendations are based on Collaborative Filtering, a standard recommender engine used.
The most famous graph databases
Data engineers need graph database tools for advanced analysis of graphs. Graph databases connect nodes and create relationships between edges in charts that can be used in queries. Central graph databases include Amazon Neptune, ArangoDB, Cayley, DataStax, FlockDB, Neo4j, OrientDB, and Titan.
Graph architecture pattern is one of the types of NoSQL databases used when building intelligent programs that require analyzing the relationships between objects or viewing all nodes in a graph. The above architecture is efficient for the efficient storage of graph nodes and optimal communication between them. In this case, data scientists can run the desired queries on the data stored as a graph.
These databases are helpful for any business with data that has complex relationships between them.
Graph databases comprise a sequence of nodes and connections that combine to form a graph. The key-value store data architecture includes two fields, key, and value. On the other hand, in a graph database, three primary data fields are used: nodes, relationships, and relationship characteristics.
When we have many elements with complex relationships, and each has its characteristics, it is appropriate to use a graph database. So that it is possible to execute simple dialogues and it is possible to identify the nearest neighbor or a more specific and complex pattern. Typically, graph nodes represent real-world objects such as names. Nodes can be people, organizations, phone numbers, web pages, computers on a network, and so on. Now let’s explore some of the most widely used graph databases and their features.
Neo4j
The most well-known open-source database management system is Graph, which is well-documented and functional. To use this database, you must be fluent in the Cypher language. Neo4j is based on horizontal scaling, which performs the reading process based on the Master-Slave pattern to increase the speed of reading information. Still, it is relatively slow in responding to requests.
Therefore, we must say that Neo4j is suitable for applications that have few write operations and many reads. The sharding technique is not used in this database because optimally dividing a large graph between several machines is expensive.
Ease of use, reducing the amount of primary memory usage, suitable for cloud computing, professional backup, flexible schema, the ability to use it with different languages that a data engineer should be familiar with, and support for Laravel, Spring, and Congo frameworks are among its advantages. Is.
OrientDB
OrientDB is one of the most robust databases in the NoSQL ecosystem. It is another popular database in this field supporting document-oriented and Graph architectures. The advantages of the OrientDB index include full support of ACID, full support of SQL language, the possibility of using RESTful without intermediaries, high speed, multi-platform, open source, the ability to manage the graph structure and charts natively, distributivity, the ability to insert into Java applications. etc., pointed out.
TITAN
TITAN is a distributed and scalable graph database. The Titan is used to sort graph data and query the optimal Graph. This database can process billions of nodes and edges distributed among several machines. The advantages of this database include elastic and linear scaling to manage a large amount of data, distribution, and replication of data to achieve better performance and fault tolerance, ACID support, back-end storage support such as HBase, BerkeleyDB, Cassandra, analysis support, Big data graph, reporting and ETL process, support for Spark, Hadoop and Apache Giraph mentioned.
ArangoDB
This database can store a JSON object as an input within a collection. Hence, there is no need to separate different JSON parts. Because of this, stored data can inherit the XML data tree structure. The key features of the above database include easy installation, the flexibility of data modeling, a robust query language for data retrieval and editing, the ability to use it as a server, the ability to reproduce and distribute data, etc.