


Today, Businesses Are Faced With An Ocean Of Data. Data Typically Obtained By IoT Sensors And Devices Located In Various Locations.
Sensors generate large amounts of data, and companies must constantly process this data. This massive volume of generated information has revolutionized how they are managed.
Is not. In traditional methods, data must be sent over the Internet to a centralized data center to be processed and returned to the source. This method works well for a limited amount of data, but when a large amount of data is to be sent to data centers, processed there, and the result returned to the source, it is not suitable because it requires a lot of bandwidth cost-effective. Bandwidth limitations, latency issues, and unpredictable network outages can disrupt the ability to send, receive, and process data.
Businesses have turned to ” edge computing ” architectures to solve this problem. Edge computing is a distributed architecture where user data is processed at the network’s edge close to the source. Statistics show that edge computing is changing the way information is processed, and there is a possibility that it will bring significant changes in the field of information technology in the future.
What is edge computing?
Edge computing moves some of the storage space and computing resources out of the centralized data center and closer to the source that generates the data. Instead of transferring the raw data to a central data center for processing and analysis, this is done at the location or source that caused the data. This resource may be an online store, a manufacturing unit, a utility, or a smart city.
In the above architecture, calculations such as initial data analysis and the possibility of strategic equipment or software problems are performed. The result is sent to the data center for a more detailed check (Figure 1).
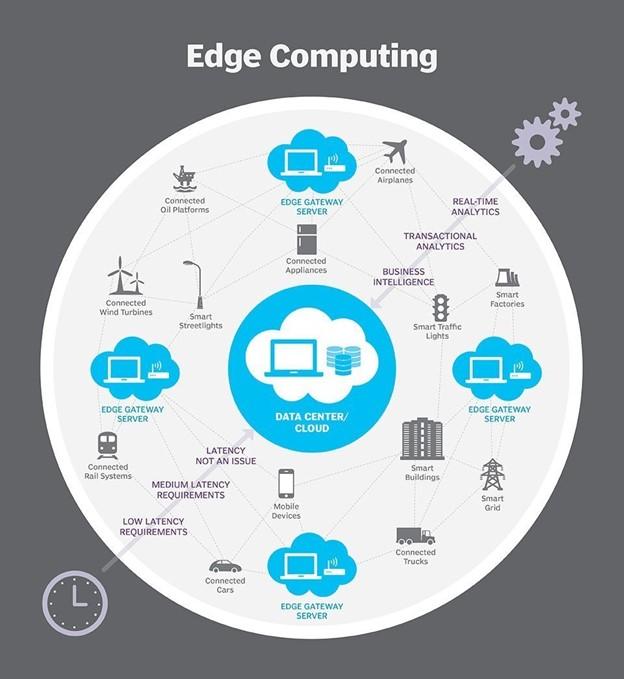

figure 1
How does edge computing work?
Edge computing is a concept that refers to a location or resource that generates data, and computing equipment is deployed in that location. In traditional enterprise computing, information is stored in equipment such as servers and then made available to users through the local network. More precisely, in the above method, the data is stored in the organizational infrastructure and processed there, and the processing results are sent to the user. The above architecture is based on most commercial applications’ client and server models.
However, the number of Internet-connected devices and the volume of data generated by the machines and used by businesses exceeds the capacity of traditional data center infrastructures.
Gartner predicts that by 2025, 75% of the data companies will interact with will be generated outside the organization. A simple example in this field is the data generated in social networks, which are of great value in business and marketing and are caused by social network users.
On the other hand, time-sensitive data is recorded by equipment such as video surveillance cameras. The images are sent over the Internet to the operator responsible for monitoring the cameras so that the operator can react if there is a suspicious case. In this method, not only a lot of bandwidth is needed to send data, but the operator must respond quickly to doubtful cases.
Suppose the image data is analyzed locally by intelligent algorithms, and suspicious cases are sent to the operator in a simple text message. In that case, it will significantly save bandwidth and reduce an incident’s response time.
In this case, there will be no additional pressure on the Internet or wide networks, and we will not face the problem of congestion and disruption.
This issue has made information technology architects go for logical edge design instead of centralized data center design. So that the storage and computing resources are transferred from the data center to a place close to the source of the data generator, it’s good to know that edge computing is based on an elementary theory. If you can’t bring the data closer to the data center, get the data center closer to the data.
Its Edge computing places storage and servers where the data resides. These types of equipment are deployed in small to medium-sized racks to collect data and perform processing locally. These racks are equipped with advanced security locks and air conditioning mechanisms so that the equipment inside the frame is not exposed to extreme temperatures, humidity, theft, or vandalism.
These small racks are often used for standard processing and analysis of business-critical data. Once they have done the calculations, they send the results to the leading data center for final research.
These days, companies, especially retailers, are working on an exciting idea combining “Business Intelligence” (Business Intelligence) and edge computing. For example, it is possible to combine the images from the video surveillance cameras in the stores with the actual sales data to present attractive offers to the consumer to purchase a product.
To be more precise, it processed the information related to purchases and visited products in real-time and then presented attractive offers to the next buyer. An approach that Amazon is working on experimentally.
Another practical example is edge-based predictive analytics. In the above method, it is possible to monitor and analyze the performance of critical facilities and equipment, such as water treatment plants and power plants, so that problems can identify and the equipment repaired or replaced before the failure occurs.
Edge, cloud, and fog calculations versus each other
One of the easiest ways to understand the differences between edge, cloud, and fog computing is to examine what they have in common. Edge computing is closely related to cloud and fog computing. Although there is overlap between these concepts, they are not the same and should not be used interchangeably. Comparing images and understanding their differences helps to use them more accurately.
All three concepts are related to distributed computing and emphasize the physical deployment of computing and storage resources near the sources that generate data. Still, the main difference between the three mentioned technologies is where the required resources should be located (Figure 2)
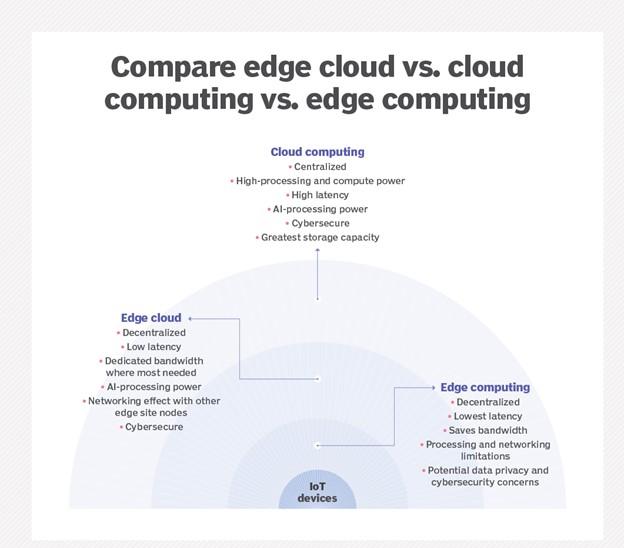

figure 2
-
Edge: in edge calculations, the process of deploying computing and storage resources is done at the location that produces the data. In the above architecture, computing and storage mechanisms are deployed right where the data source is located. For example, a small enclosure with several servers and storage equipment is installed on top of a wind turbine to collect and process data generated by sensors attached to the turbine. Another practical example in this field is a railway station that requires processing power and local storage space to collect and process rail traffic sensors, track data, and send the processing results to the next station and the central data center. In this case, the processed information is sent instead of essential information from each station to the data center, significantly impacting bandwidth consumption and faster information processing.
-
Cloud: Cloud computing refers to the massive and scalable deployment of computing and storage resources in different locations, which may be in other cities or even countries in terms of geographic location. Today, cloud computing is described as an alternative or sometimes a supplement to traditional data centers. In addition, cloud providers can prepare a set of pre-prepared services that can be used in various applications such as the Internet of Things and provide them to consumers. Hence, the cloud is an efficient centralized platform for deploying the Internet of Things. In the situation where cloud computing offers rich resources and services for complex analysis, but still the nearest cloud center may be hundreds of kilometers away from the point that produced the data, and for that reason, it is necessary to rely on high-speed communication channels on the Internet to send data to cloud using
-
Fog: Choosing an efficient architecture for computing and deploying storage is not limited to the cloud or the edge. The cloud may be far from the source of data generation, edge computing may have limited resources, or it may not be physically possible to deploy those resources on-site. A concept called fog computing was invented. Fog computing takes a step back and embeds computing and storage resources into equipment.
Fog computing environments can process large amounts of special-purpose data generated by sensors or IoT devices that may deploy over vast geographic areas that are beyond the inherent capabilities of edge computing. For example, we can refer to intelligent buildings, smart cities, or a network of innovative tools.
Consider a smart city that can use data to track, analyze and optimize the public fleet system, intra- and extra-urban services and long-term urban planning. An edge deployment is not enough to handle such a workload, so fog computing can define a set of fog nodes within the perimeter to collect, process, and analyze data.
Why is edge computing critical?
Different computing processes require their computing architectures, and it is not the case that a particular computing architecture is suitable for every task. Edge computing is a solution to overcome some limitations of cloud computing so that computing and storage resources can be placed close to the physical location of the data source so that processing can be done locally.
In general, invented distributed computing models with the goal of decentralization, but decentralization is challenging and requires high-level monitoring and control. However, edge computing is an effective solution to overcome the emerging problems that computer networks face, one of which is sending and receiving a considerable amount of information.
Since sending, receiving, and processing data requires time and some programs are time sensitive, processing information locally and sending the processed results to data centers requires less bandwidth and time.
Traffic machines and controls are forced to generate, analyze and exchange real-time data. This massive volume of data to be developed and processed requires a fast and responsive network. A concrete example in this field is self-driving cars that depend on intelligent traffic control signals.
Edge and fog computing can solve the three big problems of computer networks: bandwidth, latency, and congestion.
-
Bandwidth: Bandwidth is the amount of data a network can transfer over time and is usually calculated in bits per second. It means that the number of devices in a network can exchange a limited amount of data between each other or other networks. Networks have limited bandwidth, and the limitations are even more significant for wireless communications. Although it is possible to increase the bandwidth of the web so that more devices can add to the network and more data can transfer, this solution requires spending a lot of money and will still show its limitations in the future.
-
Latency: Latency refers to the time required to send data between two points in the network. Communication networks such as fiber optic or 5G transmit data at a very high speed. Still, long distances, the presence of various physical obstacles, and network congestion or outages can delay the data transmission process. So that the analytical and decision-making processes are delayed and the ability of the systems to respond in real-time real-times. In criticism, issue costs human lives in cases such as medicine or self-driving cars. This ision: The Internet is a network consisting of networks. Although this architecture works well for general-purpose data exchange and daily computing tasks such as file exchange or video streaming, when tens of billions of devices send and receive data simultaneously, they introduce a heavy traffic load to the Internet, causing the problem of congestion and congestion. They create. In such a situation, devices are forced to resend data, which increases congestion and may completely cut off some users’ connection to the Internet.
By deploying servers and storage equipment where data is generated, edge computing can make the performance of devices located on small local area networks more efficient, where bandwidth is used exclusively and optimally by data-generating devices, reducing latency and latency.
Density reaches its lowest value. In this case, local storage equipment collects the raw data, while l. In contrast, drivers can perform the necessary analytics on the network’s edge or at least ss the data so that only the essential data is sent to the cloud or data centers.
What are the benefits of edge computing?
Edge computing addresses critical infrastructure problems such as bandwidth limitations, excessive latency, and network congestion, but it also offers several additional potential benefits. These benefits are as follows:
-
Autonomy: Edge computing is practical when connections are unreliable or bandwidth is limited for various reasons. Some cases where edge computing performs well are oil, ships, farms, or other remote locations such as rainforests or plains. Edge computing performs computational work locally and sometimes in the device itself (such as water quality monitoring sensors installed in water treatment plants in remote villages) and can. It can only search for transmission to a central point when connectivity is available. By processing data locally, it is possible to reduce the amount of data sent, save bandwidth, or send and receive important information to and from the data center in a short time.
-
Data Sovereignty: Transferring vast data is not just a technical problem. Data transfer at border points can cause many data security and privacy issues. Edge computing can use to keep data close to the source. The above approach allows raw data to be processed locally and any sensitive data to be encrypted or unreadable before being sent to the cloud or data center so unauthorized persons cannot interpret or view it.
-
Edge security: Edge computing provides a comprehensive solution for data security. Although cloud providers offer specialized IoT services capable of sophisticated data analysis, companies are still concerned about the security of data sent to and from the cloud or data center at the network’s edge. Any data that passes through the network to the cloud or data center is encrypted by implementing an edge compete-computing.
last word
Edge computing has received attention with the ever-increasing expansion of the Internet of Things and the data generated by various devices. However, The edge will be impressive. Considering that the technologies related to the Internet of Things have not yet been fully embraced and are still evolving, this issue affects the future of computing development.
The example, for some time now, companies have offered another solution for locally computing: the story of Micro Modular Data Centers (MMDCs). MMDC is a small but complete data center that can deploy at the data generating source to perform computing processes without the need for edge computing. Of course, the above solution is in the early stages, and it is not yet clear whether it is possible to use it as an alternative to edge computing or not.