









What Are The Differences Between Supervised, Unsupervised And Reinforced Machine Learning?
Machine Learning Is A Branch Of Artificial Intelligence And Computer Science That Focuses On Using Data And Algorithms To Mimic The Way Humans Learn And Gradually Improve Its Accuracy.
IBM has a brilliant history in machine learning, and the specialists of this company have made significant achievements in this field.
One of these great experts is Arthur Samuel, who, with his research on the game of checkers, made the technology world get to know machine learning in a more detailed way.
For example, Robert Neely, the grandmaster of checkers, played against an IBM 7094 computer in 1962 and lost. Compared to what can be done today, the feat at the time pales, but the event is an essential milestone in artificial intelligence.
Over the next few decades, there were many developments in the world of technology, and the storage capacity and processing power increased.
Machine learning is one of the essential pillars of the growing field of data science. Algorithms are trained for classification or prediction and reveal critical insights in data mining-based projects.
Insights are essential in making macro business decisions and advancing business goals. As big data continues to expand and grow, the market demand for data scientists will increase. Organizations request these professionals to help them identify business strategies and how to implement them. In situations where terms such as machine learning (supervised, unsupervised, and reinforcement), deep learning, neural networks, etc. have their definitions, sometimes we see that sources or experts use these terms instead of others; Accordingly, in this article, we will tell you the differences between each of the mentioned terms.
Machine learning versus deep learning versus neural networks
Since deep learning and machine learning are used interchangeably, it is essential to understand the nuances between the two terms. Machine learning, deep learning, and neural networks are all subfields of artificial intelligence. However, deep learning is a subset of machine learning, and neural networks are a subset of deep learning.
Deep learning and machine learning differ in how each algorithm learns. Deep understanding automates much of the feature extraction process, working as much as possible without the direct supervision of experts and enabling the use of big data. In his MIT lecture, Lex Friedman pointed out an interesting point: “You can think of deep learning as scalable machine learning.
Classical or non-deep machine learning is more dependent on humans for education. Experts define a set of features to understand the difference between data inputs. In this learning model, you need structured data to train the model better.”
Deep learning can use labeled data sets, known as supervised learning, to get more detailed information, but it does not necessarily require a labeled data set. This learning model can take unstructured data in raw form (text, images) and automatically determine a set of features that distinguish different categories of data from each other.
Unlike machine learning, it does not require human intervention to process data, allowing us to scale machine learning in more exciting ways.
Deep understanding and neural networks are primarily accelerating advances in computer vision, natural language processing, and speech recognition.
In the past few decades, when computers gained the ability to implement computational algorithms in line with simulating the computational behavior of the human brain, a lot of research, the results of which are in a branch of artificial intelligence science.
And in the sub-branch of computing intelligence called “Artificial Neural Networks,” ANNs manifested themselves as Artificial Neural Networks. Typically, artificial neural networks process information based on different layers and can include an input layer, one or more hidden layers, and an output layer.
Each node (artificial neuron) is connected to another node and has its weight and threshold. If the output of any individual node exceeds the specified threshold value, that node is activated and forwards the data to the next layer of the network. Otherwise, no data is transmitted to the next network layer. The word deep in deep learning only refers to the depth of the layers.
A neural network with more than three layers, inputs, and outputs can be considered a deep learning algorithm or a deep neural network. A neural network that has only two or three layers is a primitive neural network.

How does machine learning work?
UC Berkeley divides the learning mechanism of a machine learning algorithm into three main parts as follows:
Decision-making process: Generally, machine learning algorithms are used for prediction or classification. The algorithm estimates a hidden pattern in the data based on some input data that can be labeled or unlabeled.
Error function: An error function is used to evaluate the model’s prediction. An error function can compare if there are known samples to assess the model’s accuracy.
Model optimization process: If the model can better match the data points in the training set, the weights are adjusted to reduce the difference between the examples and the model estimate. The algorithm repeats this evaluation and optimization process and updates the weights independently until an accuracy threshold is reached.
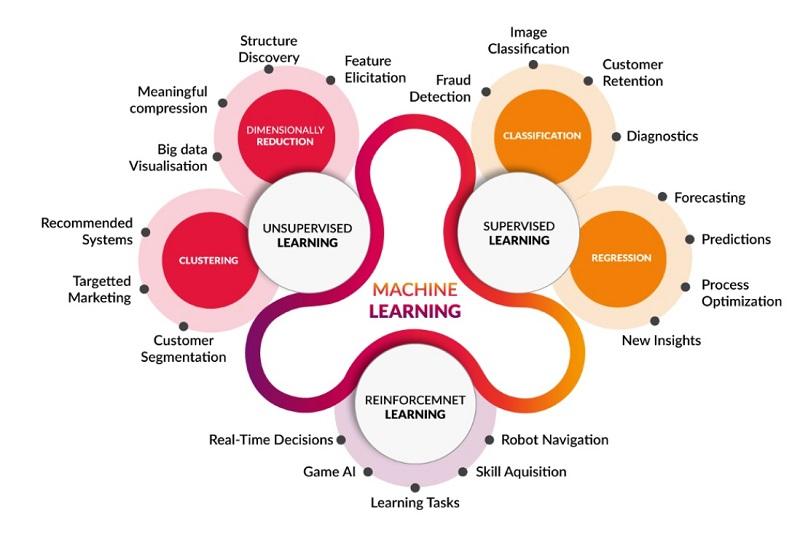
Machine learning methods
The classification paradigms governing machine learning are divided into the following three main categories:
Supervised machine learning
Supervised learning uses labeled datasets to train algorithms to classify data or accurately predict outcomes. The weights are adjusted until the model fits correctly as input data is fed into the model.
The above approach is part of the cross-validation process to ensure that the model does not suffer from overfitting or underfitting. Supervised learning helps organizations solve large-scale real-world problems, most notably directing the classification of spam into a separate folder from the email inbox.
There are various algorithms under the umbrella of supervised learning, including support vector machines and simple Bayes. Some methods used in supervised learning are Neural Networks, Simple Bayes, Linear Regression, Logistic Regression, Random Forest, Support Vector Machine (SVM), etc. You can see the two steps of constructing and testing a mapping function with supervised learning in Figure 1.
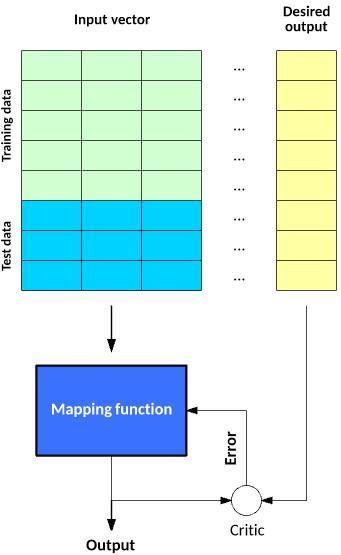
figure 1
Unsupervised machine learning
Unsupervised learning of machine learning algorithms is used to analyze and cluster unlabeled data sets. These algorithms discover hidden patterns or groupings of data without the intervention of experts.
The algorithms mentioned above can discover similarities and differences in information to provide an ideal solution for exploratory data analysis, cross-selling strategies, customer segmentation, and image and pattern recognition. Also, they use the dimensionality reduction technique to reduce the number of model features.
Principal Component Analysis (PCA) and Singular Value Decomposition (SVD) are two common approaches used by unsupervised algorithms. Neural networks, k-means clustering, probabilistic clustering methods, etc., are prominent algorithms in this field. Figure 2 shows the performance of the above technology.
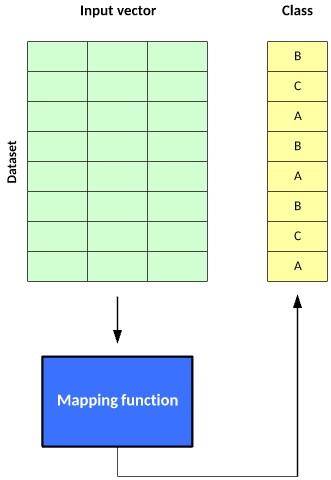
figure 2
Semi-Supervised Learning
Semi-supervised learning is on the border between supervised and unsupervised learning. In the above model, a small and concise labeled data set is used to help the model classify and extract features in a more extensive, unlabeled data set. Semi-supervised learning can solve the problem of not having enough labeled data (or not being able to afford to label enough information) to train a supervised learning algorithm.
Reinforcement Machine Learning
Reinforcement machine learning is a machine learning model that is a behavior similar to unsupervised learning, but the algorithm is not trained using sample data. This model learns using trial and error.
In the above approach, the model learns how to provide the best performance based on reward or punishment. So that a sequence of successful results is used to implement the best recommendation or policy for a particular problem, IBM’s Watson system, which won the 2011 Jeopardy TV competition, is the best example of this.
The system used reinforcement learning to decide whether to answer or ask a question and determine which square to choose on the board. It is necessary to explain that reinforcement learning has two trends: Deep Reinforcement Learning and Meta Reinforcement Learning.
Deep Reinforcement Learning (Deep Reinforcement Learning) uses deep neural networks to solve reinforcement learning problems, so the word deep is used. Q-Learning is considered classical reinforcement learning, and Deep Q-Learning, regarded as a newer example, is related to this field.
In the first approach, traditional algorithms construct a Q table to help the agent find what to do in each situation. The second approach uses the neural network (to estimate the reward based on the state: q value).
Figure 3 shows the reinforcement learning model. In the first approach, traditional algorithms construct a Q table to help the agent find what to do in each situation.
The second approach uses the neural network (to estimate the reward based on the state: q value).
Figure 3 shows the reinforcement learning model. In the first approach, traditional algorithms construct a Q table to help the agent find what to do in each situation. The second approach uses the neural network (to estimate the reward based on the state: q value). Figure 3 shows the reinforcement learning model.
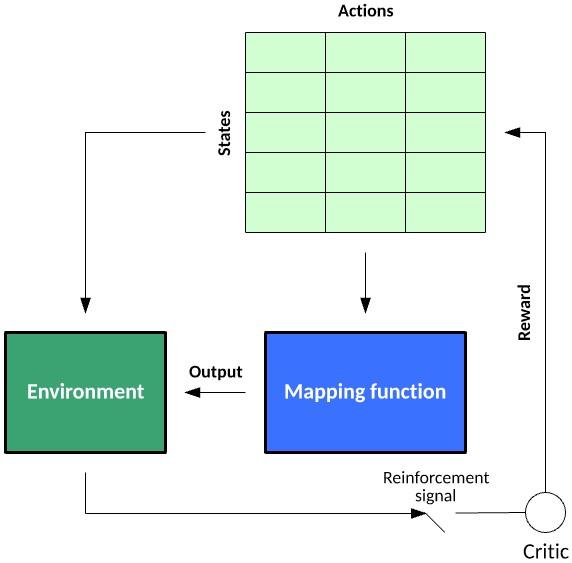
Figure 3
Neural networks
The neural network processes an input vector based on a model inspired by neurons and their connections in the brain. This model consists of layers of neurons connected through weights that can recognize the importance of specific inputs. Each neuron contains an activation function that determines its output (as a function of its input vector multiplied by its weight vector).
The output is calculated by applying the input vector to the network’s input layer and then summing each neuron’s work through the network (feedback). Figure 4 shows the layers of a standard neural network.
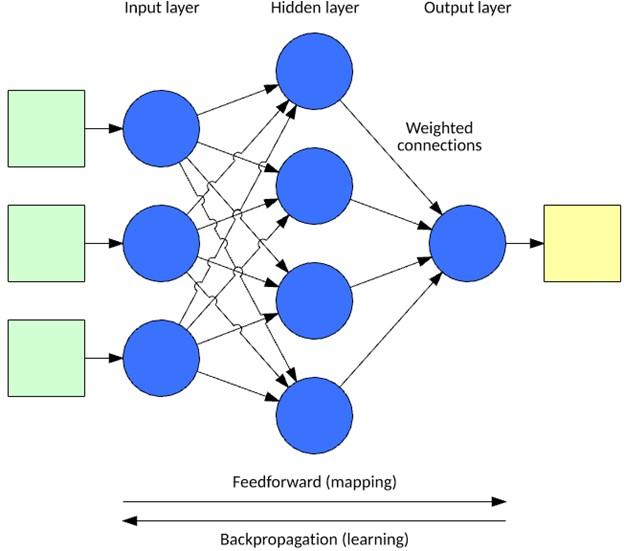
Figure 4
Back-propagation is one of the most popular supervised learning methods for neural networks. In post propagation, you have an input vector for data injection and an output vector for computation. In the above pattern, the error is computed (actual vs. arbitrary), then propagated twice to adjust the weights from the output layer to the input layer (as a function of their contribution to the output, setting the learning rate).
decision tree
A decision tree is a supervised learning method used in classification that provides the result of an input vector based on decision rules inferred from the features in the data. Decision trees are valuable because they are easy to visualize, so you can see and understand the factors that drive outcomes. Figure 5 shows an example of a shared decision tree.
Decision trees are divided into two main types. Classification trees where the target variable is a discrete value and leaves represent class labels (as shown in the tree in Figure 5) and regression trees where the target variable can take continuous values. You use a dataset to train the tree and then build a model from the data. Then, you can use the tree to make decisions about unseen data.
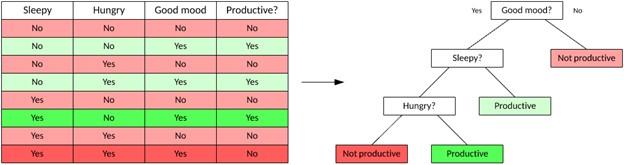
Figure 5
There are various algorithms related to decision tree learning. One of the essential options in this field is ID3, named Dichotomiser 3, which divides the data set into two separate data sets based on a single area in the vector.
You select this field by calculating its entropy (a measure of the distribution of the values of that field). The goal is to choose a lot of the vector that leads to entropy reduction in subsequent divisions of the dataset during tree construction.
Other algorithms in this field include Beyond ID3, the improved and alternative ID3 algorithm called C4.5, and the MARS algorithm called Multivariate Adaptive Regression Splines, which build decision trees with improved numerical data management.
last word
Machine learning consists of various algorithms used according to a project’s needs. Supervised learning algorithms learn a mapping function for an existing classified dataset, whereas unsupervised learning algorithms can classify unlabeled datasets based on hidden features. Finally, reinforcement learning can learn policies for decision-making in an uncertain environment through continuous exploration of that environment.