


Data masking is the process of hiding original data, and its main purpose is to hide sensitive data such as personal data stored in the original database.
The important point, however, is that data remains usable in data masking.
Data masking is the process of hiding original data, and its main purpose is to hide sensitive data such as personal data stored in the original database. The important point, however, is that data remains usable in data masking.
What is data masking?
Data Masking means to cover or obscure data. This method is actually a trick to create fake copies of the organization’s original data that, although fake, still look real.
Among its goals, we can mention the protection of sensitive data and the creation of useful data in situations where we do not need the original data (for example, when the data is needed for training, software testing, program demo sales, etc.).
In fact, the Data Masking process changes the amount and value of the data while preserving the format so that this created version of the data cannot be detected using decryption or reverse engineering. There are several ways to change the data, which we will explain below.
Why and when to use Data Masking?
One of the most important reasons why organizations turn to Data Masking is to solve many security problems such as data loss, data theft (data exfiltration) and …. Other reasons for using this security method include reducing the risks of using the cloud, rendering data unusable for hackers (while many intrinsic properties of the data have been retained), allowing data to be shared with authenticated users.
Identified (for example, for testers, developers, etc.) without disclosing the original data, the data is erased (in fact, even when it deletes the data, a trace of it remains, which is itself a reason for the possibility of data recovery.
Data structuring means that real data is replaced by masked data.
Sometimes an organization needs to allow external resources and third-party organizations active in the field of IT to use its databases. In this case, you need to ensure the security of the data in such a way that for these people and even hackers, the data looks completely real and not suspicious.
Sometimes an organization needs to reduce the error of its operators. Organizations often rely on their employees to make the right decisions, yet many of the shortcomings that arise are the result of human error. If data is masked in a certain way, it can reduce catastrophic errors.
Organizations that work with sensitive data such as user identification information (PII), personal medical information (PHI), personal account and bank card information (PCI-DSS), intellectual property information (ITAR), etc., can benefit from data masking To take.
Types of Data Masking
Data masking is used in several different ways to maintain data security, including Static Data Masking, Deterministic Data Masking, On-the-Fly Data Masking, and Dynamic Data Masking. In the following, we will explain each one.
Static Data Masking
This way you can have a copy of the deleted database. During this process, virtually all sensitive data is modified to create a copy of the database that we can share with security. Usually in this method we first take a copy of the database as a backup, load it in a different environment, delete all the extra information and then mask the remaining data. Masked data can now be moved to the target point.
Deterministic Data Masking
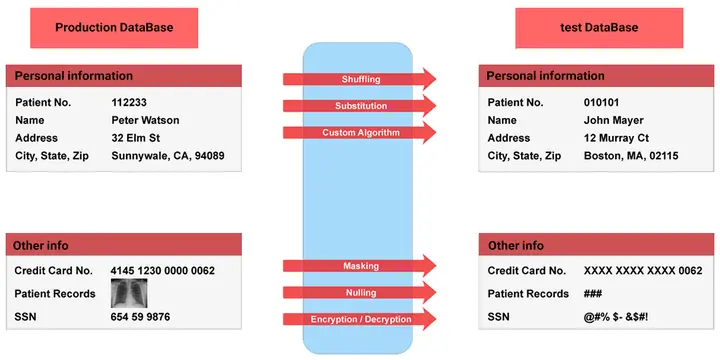
In this method, we actually have two sets of data of the same type and format, one of which is always replaced by another. For example, anywhere in the database, the name “John Smith” is always replaced by the name “Jim Jameson”.
On-the-Fly Data Masking
This method is actually data masking at a time when data is being transferred from production systems to test or development systems and has not yet been saved on disk.
Organizations that deploy software quickly can not make a backup copy of the source database and apply data masking to it, and need to constantly stream data from production to multiple test environments. In the On-the-Fly method, each part of the masked data that is needed is sent. Each part of this masked data is then stored in a test or development environment for use by a non-productive system.
Dynamic Data Masking
This method is almost identical to the On the fly method, except that the data is not stored in any secondary point such as the test or development environment. In other words, the data is sent directly from the production system as a stream for system consumption in the test or development environment.
Data Masking Techniques
Organizations can use a variety of techniques to mask their sensitive data, and here are some of the most commonly used techniques.
Data Encryption
When data is masked by cryptographic algorithms, the user is virtually unable to use the data without having a key. This technique is the most secure form of data masking, but it is difficult to implement because we need data encryption technology as well as a secure key sharing mechanism.
Data Scrambling
This technique is very simple and only replaces all the characters in the phrases randomly. For example, a number like 76498 changes to 84967. Although this technique is very simple, the problem is that it is not possible to use it on all data and of course its security is not very high.
Nulling Out
In this method, when the user has unidentified data requests, the value Null (data that has no value or is lost) is displayed to him. The disadvantage of this method is that for the purpose of testing and development, less data can be used.
Value Variance
In this case, the original data value is replaced using a function (for example, the difference between the maximum and minimum values in a series). For example, if a customer has purchased multiple products, we can replace the purchase price with the average price of the most expensive and cheapest product purchased by him.
This technique, while not disclosing the original data, gives us a very useful value that we can use for different purposes.
Data Substitution
In this method, the original value of the data is replaced with false but true values. For example, we randomly replace customer names with a number of names in a phonebook.
Data Shuffling
This method is very similar to Data Substitution, except that the data in a database is replaced by data from the same database. In fact, the order of the data in each column changes. In the end, the output from this database looks quite real, but the records are not real at all.

The best data masking tools
Among the best Data Masking tools we can mention the following:
DATPROF – Test Data Simplified
Microsoft SQL Server Data Masking
Oracle Data Masking and Subsetting
IBM InfoSphere Optim Data Privacy
And..