










The Structure Of The Internet And The Unipartite Routing Protocols At Its Heart
Unicast Routing Protocols Play An Important Role In The Structure Of The Internet. These Protocols Minimize The Rate Of Data Loss By Providing An Optimal Mechanism For Sending And Receiving Packets.
Routing Protocols, By defining their operational domain, protocols can manage messages and communicate routers with each other.
In addition, protocols communicate with each other to route and send packets from source to destination nodes.
Today, Routing Information Protocol (RIP) based on Distance Vector Algorithm, Select Shortest Path First (OSPF) based on Link State Algorithm, and Border Gateway Protocol (BGP) based on Path Vector Algorithm are more than Other protocols are used on the Internet.
The structure of the Internet
Before discussing unicast routing protocols, we need to understand the current structure of the Internet. Although it is difficult to provide an overview of the Internet today, it can say that the Internet has a system similar to what you see in Figure 1. The Internet has changed from a tree-like form with a single backbone to a multi-column facility run by various private companies.
As you can see, several backbones are managed by private telecommunications companies to enable global connectivity. These columns are connected by some peering points that allow connection between the spines.
At a lower level, some service provider networks use backbones to establish global communications and, in addition, provide services to Internet users. Finally, there are consumer networks that use services provided by provider networks. Each of these three entities (broker, network provider, and client network) can be called an “Internet Service Provider” (ISP) that provides services at different levels.
The current Internet consists of many networks and routers that connect local and wide area networks with other equipment. Routing on the Internet using a protocol is impossible due to scalability and management complexity. More precisely, if only one protocol is used, it becomes impossible to achieve scalability because the size of the forward tables becomes large, the destination lookup in the forwarding tables takes time, and updating many tables creates heavy traffic.
As Figure 1 shows, each ISP is governed by a management authority that must completely control its infrastructure. Also, the organization responsible for managing a specific segment must possess several routers.
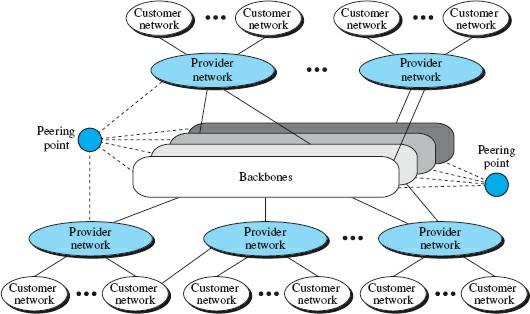
figure 1
Hierarchical routing means considering each ISP as an Autonomous System (AS). Each AS can invoke and implement a routing protocol to meet its needs, but the Internet uses global protocols to connect all running autonomous systems. The routing protocol used in each AS is called the intra-entity routing protocol, or the “Interior Gateway Protocol” (IGP).
In contrast, Global Routing Protocol is called Autonomous Systems Routing Protocol or “External Gateway Protocol” (EGP). We can have multiple intra-domain routing protocols and let each autonomous system choose its preferred option. Still, we should have only one inter-domain protocol that handles routing between these nodes. Currently, two standard intra-domain routing protocols, RIP and OSPF, and inter-domain routing protocol BGP are widely used. It is necessary to explain that the conditions may change whenever the IPv6 protocol becomes widespread.
Autonomous systems
As mentioned, each ISP is an independent system for managing the networks and routers under its control. Although we may have minor, medium, and large autonomous systems, each autonomous system is assigned an Autonomous System Number (ASN) by the ICANN organization. Each ASN is a 16-bit unsigned integer that uniquely defines an independent system. However, autonomous systems are not classified by size or smallness. They are ranked based on how they connect to other autonomous systems.
Accordingly, today we have small, transitory, and multi-home autonomous systems.
- Stub Autonomous Systems: An autonomous stub system can be connected to only one other independent system. In most cases, data traffic is contained within the autonomous system and does not support forwarding data traffic. An excellent example of a micro-autonomous system is a client network, a data source or repository designed only to meet the needs of specific clients.
- Multi-home Autonomous Systems: A system with more than one connection to other autonomous systems does not allow data traffic to pass through it. An excellent example in this context is autonomous client systems that use the services of more than one service provider network, but their policy does not allow data to pass through them.
- Transient Autonomous Systems: A transient autonomous system is connected to various techniques and allows traffic to be sent. Service provider networks and Internet backbones are good examples of temporary autonomous systems.
Routing Information Protocol (RIP)
Routing Information Protocol is one of the most widely used intra-domain routing protocols developed based on the distance vector routing algorithm. RIP was developed as part of the Xerox Network System, but further changes making based on the Berkeley Software Distribution of Unix to make RIP widely used.
Hop Count
Since a router in an autonomous system needs to know how to send a packet to different networks (subnets) in an independent system, it needs to calculate the cost of accessing various networks based on graph theory to calculate the charge between the router and the web, where the destination host is located.
The cost is calculated based on the number of hops the packet has passed through. To be more precise, the distance between the source and destination router is calculated. The vital thing to note is that the network where the source host is located is not calculated because the source host does not use the forwarding table.
In Figure 2, the number of hops equals 3, meaning there are three routers between the source host and the destination host. In RIP, the maximum cost of a route can be 15, so values above 15 are considered infinite (no connection). For this reason, RIP can only use in autonomous systems with no more than 15 hops.
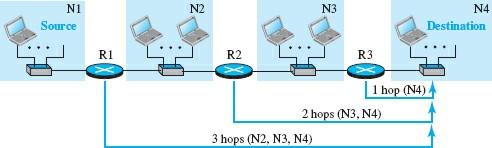
figure 2
Forwarding Tables
Although the distance vector algorithm works around sending distance vectors between neighboring nodes, routers in an autonomous system must maintain forwarding tables to send packets to destination networks accurately. The forwarding table in RIP is a three-column table in which the first column is the address of the destination network, and the second column is the address of the next router. The third column is the cost (number of hops) to reach the destination network.
In Figure 3, you can see an example of forwarding tables of routers. As you can see, the first and third columns have similar information related to the distance vector and show the number of hops to reach the destination network.
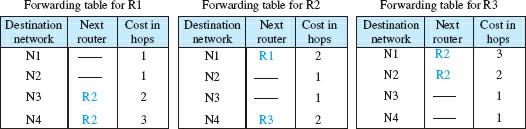
Figure 3
Although a forward table in RIP only defines the next router in the second column, it shows the complete low-cost tree information based on the second attribute of the trees. For example, R1 represents that the next router for route N4 is R2. R2 defines that the next router to N4 is R3. R3 limits that there is no next router for this route. So the tree will be R1 → R2 → R3 → N4. A question that is often asked about the forward table is what is the use of the third column. The third column is not needed to forward the packet but is required to update the forwarding table when a change occurs in the path.
RIP implementation
The RIP is implemented as a process that uses the User Datagram Protocol (UDP) service on port 520. Though RIP is a routing protocol that helps IP send its datagrams through the autonomous system, RIP messages are encapsulated in the UDP protocol. Interestingly, the UDP protocol itself is enclosed in IP datagrams. In BSD, the RIP protocol runs a procedure called a daemon.
In other words, RIP runs at the application layer but continues to create forwarding tables for IP on the network. So far, two versions of RIP named RIP-1 and RIP-2 have been released, and the second version is compatible with the first version.
RIP messages
RIP processes need to exchange messages. A part of the message, which we call input, can be repeated in a message if required. The format of RIP-2 messages is shown in Figure 4. Each entry contains information about a line in the router’s forwarding table that forwarded the message.
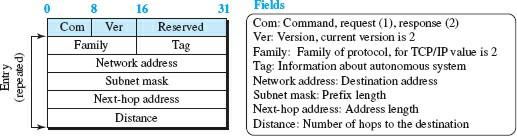
Figure 4
RIP has two types of request and response messages. A request message is sent by a newly executed router or a router with some timed entries. A request message asks about specific entries or all entries. A response (or update) statement can be either solicited or unsolicited. A request-response message is sent only in response to and contains information about the destination specified in the corresponding request message. On the other hand, an unsolicited response message is sent periodically, every 30 seconds, or when a change occurs in the forwarding table.
RIP algorithm
RIP implements the distance vector routing algorithm. However, it makes two changes to the algorithm so that the router can update its forwarding table:
1. A router SHOULD send the entire contents of its forwarding table in a reply message instead of only sending distance vectors.
2. The receiver adds one hop to each cost and changes the Next Router field to the sender’s router address. We call each route in the modified routing table a “Received Route” and each route in the old routing table an “Old Route.” In this case, the receiving router selects the ancient routes as the new routes.
There are only three exceptions as follows:
- If the received route does not exist in the old forwarding table, it is added to the course.
- If the cost of the received route is lower than the cost of the previous route, the accepted route should be selected as the new route.
- If the cost of the received route is higher than the cost of the previous route, but due to some criteria, both routes have the exact cost for the next router, then the received route should be selected as the new route. This state only occurs when the router used the same route in the past, but its status has changed. For example, suppose a neighbor previously sent a route to a destination with a cost of 3, but now there is no route between this neighbor and the destination. The neighbor sends this destination with an infinite cost value (16 in RIP). The receiving router should not ignore this value, even if its old route has a lower cost to the same destination. In this case, the new forwarding table should be sorted by destination route. Figure 5 shows the operation of RIP in an autonomous system.
- First, the format of all forwarding tables is the same after all routers are booted.
- Next, changes are made to some tables when some update messages are sent and received.
- Finally, fixed forward tables are built until no change occurs.
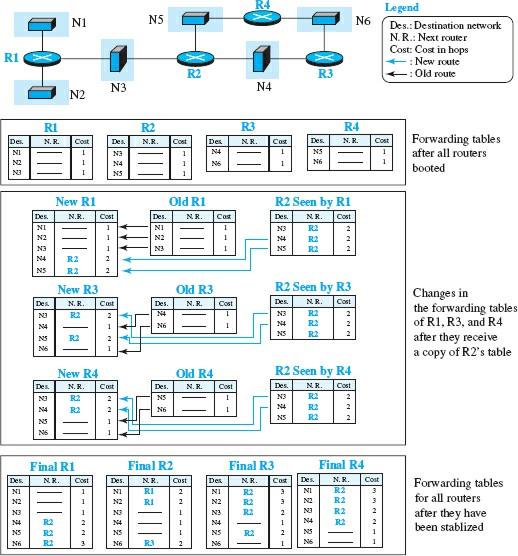
Figure 5
Timer in RIP
RIP uses three timers to maintain performance.
- The first timer is the periodic timer that controls the process of sending update messages. Each router has a regular timer randomly set to a number between 25 and 35 seconds (to avoid all routers sending messages simultaneously and causing extra traffic).
- The second timer is Timer Counts Down. An update message is sent when it reaches zero, and the timer is reset randomly once again.
- The third timer is the Expiration Timer, which checks the validity of a route. Each course has its expiration timer. When the router receives update information for a period, the expiration timer for a particular way is set to 180 seconds. The timer is reset each time a new update is received for the route. If there is a problem with the Internet and no update is received within 180 seconds, the way is considered “lost,” and the hop count of the route is set to 16, which means the destination is unreachable.
The Garbage Collection Timer is used to clear a route from the forwarding table. When a route’s information becomes invalid, the router does not immediately delete that route from its table but continues broadcasting the road with a metric value of 16. At the same time, the garbage collection timer for that route is set to 120 seconds. When the count reaches zero, the way is deleted from the table. This timer allows neighbors to be notified that a route is invalid before being purged.
RIP protocol functionality
Regarding RIP implementation, performance is an important issue that should not be overlooked.
In this context, three important concepts should be considered when implementing RIP:
- Update Messages: Update messages in RIP have a simple format and have a local approach. More precisely, neighboring nodes send these messages to each other and thus do not create traffic because routers try not to send these messages at the same time.
- Convergence of Forwarding Tables RIP uses a vector-distance algorithm to converge if the range is extensive gradually. Since RIP only allows 15 hops in a domain, there is no convergence problem. The only problem that may negatively affect the convergence process is loops created in the environment or numbers up to infinity. Solutions such as poison-reverse and split-horizon have been added to the RIP protocol to solve this problem.
- Integrity: As we mentioned, distance vector routing is based on the concept that each router sends what it knows about the entire domain to its neighbors. It means that the calculation of the forwarding table depends on the information received from the direct neighbors, who in turn receive their information from their neighbors. Consequently, if one router has a problem, the problem is transmitted to all routers and negatively affects the forwarding process of each router.