


In The Internet, The Network Layer Is Used To Deliver Datagrams From The Source To One Or More Destinations.
If the datagram is sent to only one destination, we have a one-to-one delivery pattern called unicast routing.
If the datagram is sent to multiple destinations, we have a multicast routing, one-to-many delivery.
In communication networks, routing is possible if the router has a forwarding table to forward the packet to the next node in the path to reach the destination.
To build forward router tables, the Internet uses various routing protocols that have a dynamic state. Routers’ routing tables are constantly updated.
What is routing?
Unicast routing is done on the Internet with many routers and hosts and is based on hierarchical routing and in several stages using routing algorithms. In unicast routing, the packet is forwarded from source to destination and from one hop to the next through forwarding tables.
The source host does not need to send the table because it delivers its packet to the default router on the local network. The destination host also does not need to send the table because it receives the package from the default router on the local network.
It means only routers connecting networks on the Internet need forwarding tables. With the above explanation, we must say that routing a package from the origin to the destination means routing The packet from the source router (the source host’s default router) to the destination router (the router connected to the destination network).
Although a packet must pass through the source and destination routers, the question is what other routers the package must pass through, or in other words, how many paths a packet takes from the source to the destination.
The Internet can be imagined as a graph to find the best route. To model the Internet as a graph, we can think of each router as a node and each network between a pair of routers as an edge. The Internet is modeled as a weighted graph where each edge has a cost. If a weighted graph represents a geographic region, nodes can be cities, and borders can be roads that connect cities. The weights, in this case, are the distances between cities. However, in routing, the cost of an edge is different in different routing protocols. Suppose there is a cost for each bite. If there are no edges between nodes, the price is infinite. Figure 1 shows how the working mechanism of the Internet is drawn in the form of a graph.
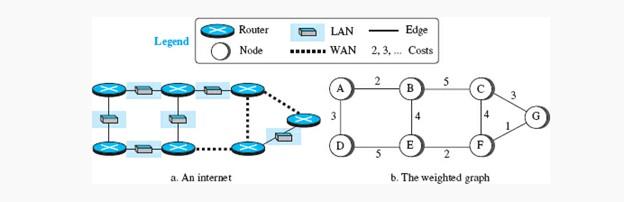

figure 1
Routing with the lowest cost
When we model the Internet as a weighted graph, one way to interpret the best route from an origin router to a destination router is to calculate the least cost between the two points. In other words, the source router chooses a path to reach the destination router so that the total cost of the route is the lowest among all possible ways. Figure 1 shows the best path between A and E is ABE with cost 6. Each router must find the least-cost path between itself and other routers to send the packet to the destination in the shortest time.
Least-Cost Trees
If there are N routers on the Internet, (N-1) represents the least-cost paths from each router to each other. We need N×(N-1) low-cost courses, so that network bandwidth is not wasted. For example, if we only have ten routers on the Internet, we need 90 low-cost routes. A better way to visualize these paths is to combine them into a low-cost tree. A low-cost tree is a tree with the source router as the root, which is visited by all nodes in the network, and where the path between the heart and each node is the shortest.
A tree will have the shortest path for each node in this case. In the real world, we have N least-cost path trees for the entire Internet. However, some of them are more important. Figure 2 shows seven low-cost trees used on the Internet.
Minimum cost trees for a weighted graph can have several important properties.
The least-cost path from X to Y in tree X is the inverse of the least-cost path from Y to X in tree Y. The cost is the same in both directions. For example, in Figure 2, the path from A to F in tree A is (A → B → E → F), but the path from F to A in tree F is (F → E → B → A). In each case, the cost is equal to 8.
Instead of moving from X to Z using the X tree, we can move from X to Y using the X tree and continue from Y to Z using the Y tree. For example, in Figure 2, we can move from A to G in tree A using the path (A → B → E → F → G). Also, we can go from A to E in tree A (A → B → E) and then continue in tree E using the path (E → F → G). The combination of the two paths in the second case is the same as in the first. As a result, the cost in the first case is nine, and in the second case, it is 9 (6 + 3).
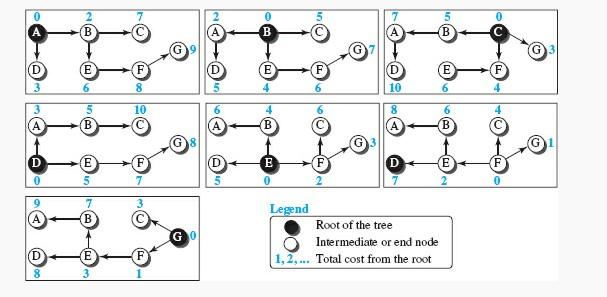

figure 2
Routing algorithms
Low-cost trees and forwarding tables are vital components the network protocol uses to send packets at the lowest cost. Routing algorithms are another essential component that plays a crucial role in this field. Until now, various routing algorithms have been designed. These algorithms differ in interpreting the least cost and creating the most diminutive cost tree for each node.
Distance vector routing
Distance-Vector (DV) routing is used to find the best route. In distance vector routing, the first thing each node creates is its least-cost tree with the basic information it has about its nearest neighbors. Incomplete trees are sent and received between neighbors to gradually become more and more complete trees usable on the Internet. In distance vector routing, a router continuously informs all its neighbors about what it knows about the entire Internet, even if this information is incomplete. Before we show how low-cost incomplete trees can be combined to form complete trees, we need to address two critical topics, the Bellman-Ford equation and the concept of distance vectors.
Bellman-Ford equation
At the heart of distance vector routing is the famous Bellman-Ford equation. This equation is used to find the lowest cost (shortest distance) between the source node x, the destination node y, and through some intermediate nodes (a, b, c) to calculate the cost between the source and the intermediate nodes and the lowest price between the nodes Obtain the intermediary and destination of the data. In the formula below, Day represents the shortest distance.
Dxy=min{(cxa+Day), (cxb + Dby), (cxc + Dcy), …}
In distance vector routing, we consider updating the available minimum cost with the lowest cost via an intermediate node, such as z, to see if the second node is shorter. In this case, can write the equation in the following simpler form:
Dxy = min {Dxy, (cxz + Dzy)}
The graphic representation of the Bellman-Ford equation is shown in Figure 3.
Let’s implement new from previous low-cost trees. The Bellman-Ford equation allows us to construct a new least-cost path from previous least-cost paths. In Figure 3, we can consider (a → y), (b → y), and (c → y) as the previous least-cost paths and (x → y) as the new least-cost path, and the new equation as the constructor of a least-cost tree. In other words, using this equation in distance vector routing proves that low-cost trees are used in this method to find the best route.


Figure 3
Distance vectors
Distance vector forms the basis of distance vector routing.
A low-cost tree combines paths from the tree’s root to all destinations.
These paths are graphically connected to form a tree.
Distance vector routing opens these routes to define a distance vector and a one-dimensional array to represent the tree.
Now we know that a distance vector can represent the least-cost paths in a least-cost tree, but how does each node on the Internet create the corresponding vector. When it enters the operational phase, each node in the Internet creates a direct distance vector with minimal information obtained from its neighbor node. The node sends hello messages to its neighboring interfaces to discover the identity of its neighbors and the distance between itself and each neighbor. Next, inserting the discovered lengths in the corresponding cells creates a simple distance vector and considers the value of the other cells to be infinite. Do these distance vectors represent low-cost paths? It looks like this at the beginning. At the beginning of the work, the initial path is considered the least expensive when we only know the distance between two nodes. However, as the information is complete, a more accurate understanding of the least costly path is obtained gradually. Figure 4 shows the distance vectors that the Internet uses. Pay attention that these vectors are created asynchronously.
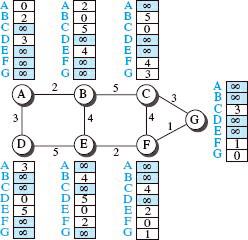

Figure 4
These elementary vectors cannot help the Internet network to send a packet optimally. In Figure 4, node A assumes it is not connected to node G because the corresponding cell shows the lowest infinite cost. To improve the performance of these vectors, nodes on the Internet must help each other by exchanging information. After each node has created its vector, it sends a copy of the vector to all its nearest neighbors. After a node receives the distance vector from its neighbor, it updates its vector using the Bellman-Ford equation (case 2).
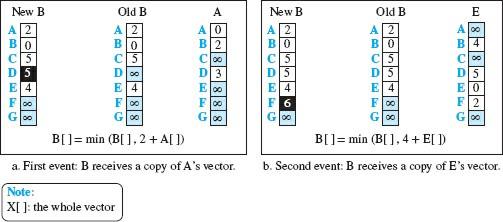

Figure 5
In Figure 5, we see two non-synchronous events that happen one after the other with a time interval. In the first event, node A sends its vector to node B. Node B updates its vector using cost CBA = 2. In the second event, node E sends its vector to node B, and node B updates its vector using cEA = 4. After the first event, the vector of node B improves slightly, and its minimum cost to node D changes from infinity to 5 (via node A). After the second event, the vector of node B improves again, and its minimum cost for node F changes from infinity to 6 (via node E). The exchange of vectors ultimately stabilizes the network’s performance and allows nodes to find the minimum cost between themselves and every other node. Note that the updated vector is immediately sent to all neighbors after updating a node. Even if the neighbors have the previous vector, they will still receive the updated version. Simplified pseudocode for the algorithm instance vector routing is shown in Figure 6. The mentioned algorithm is executed by each node independently and asynchronously.


Figure 6
Lines 4 to 11 initialize the node vector. Lines 14 to 23 show how to update the current vector after receiving a new vector from a neighbor. The for loop in lines 17 through 20 allows all entries (cells) in the vector to be updated after receiving the new vector. Note that the node sends its vector in line 12 after initialization and line 22 after updating.