


What is a Robots.txt file? As we all know, search engine bots play the most prominent role in fully introducing a site to search engines. As the biggest reference and the most extensive network in this field, Google has developed many private and public bots. Successful webmasters always follow the performance and changes of these robots and advance according to their standards.
But how do these robots access different sites? How can we limit the access of these robots to certain content or pages of our site or give them full access? For this, there is a simple yet incredibly important technique. This technique is the use of a text file called Robots.txt, which can be used to insert commands on the web to do various things, including creating access or limiting search engine robots.
The importance and optimization of this file can play a very useful role in the development of your internet site, and on the contrary, carelessness in working with it, may easily make your site rank several times worse. In this article, we intend to introduce you to the nature of Robots.txt files and to tell you their great importance for better success in SEO processes.
What is a Robots.txt file?
A Robots.txt is actually a simple text file that is placed in the main path of your site or the root directory. In fact, the task of this file is to introduce the accessible sections and the restricted sections for the access of robots or with a more precise definition, the web crawlers (Web Crawlers) created by search engines in order to check and record the information of the sites.
By inserting specific commands in this file, you can tell the search engine bots which pages, which files, and which sections of your site to see and index and which pages to ignore. In other words, the first thing that search engine robots encounter is this Robots.txt file. As soon as they encounter this file, web crawlers start checking the content and list inside this file to find the accessible parts.
As mentioned, this file should be located in the main root of your host. In this case, the address to access this file will be as follows:
www.YourWebsite.com/robots.txt

What happens if your site doesn’t have a robots.txt file?
If this file is not uploaded to your site’s host, crawlers and search engine bots will have access to all public pages and will be able to index all of your site’s content.
What if the Robots.txt file is not prepared and uploaded correctly?
The outcome of this case will depend on the type of problem. If the said file is not created in a standard and correct format, or the information and commands inside it are not able to be recognized, search engine bots will continue to access your site’s information and can index it. In other words, robots change their behavior only when they have received the exact order corresponding to that behavior through the texts inside this file. Otherwise, they will continue their normal behavior of crawling and indexing all parts of the site.
The Most Important reasons to use robots.txt
With the help of this file, you can manage the access of search engines
Limiting the access of search engine crawlers to selected pages, files and content of sites is the most common reason to use robots.txt file. If you have the question why we should not index some pages or files, the answer should be that in many cases, indexing and introducing a page or file from a site in search engines can lead to inappropriate results.
For example, maybe a webmaster wants to publish a special article, and the audience of that article is also special and selected people. This article may, in some circumstances, violate some of the rules of search engines or contain content that cannot be presented publicly. In this case, you can limit the access of search engines to these pages or files with the help of the Robots.txt file.
The most obvious examples in this field are illegal file-sharing sites, including torrent sites. Many of these sites do not allow search engine bots to access their internal content and instead offer users their own internal search engine. Because if the content of these sites is detected by robots, these sites will not only lose their rank and position in search engines due to the provision of illegal content but they will also be troubled by issues related to copyright rights and similar issues.
Failure to use the robots.txt file can lead to a decrease in the site’s optimal performance
Active websites, especially large and popular websites, are visited and reviewed thousands of times daily by various robots from search engines. Each robot or so-called crawler collects information from sites during a two-step process (checking and then indexing). This process includes checking all parts of your site. Now suppose that hundreds or thousands of robots start checking and collecting information from your site on a daily basis, and in this case, the optimal performance of your site and the speed of loading information for browsers will be overshadowed.
It is obvious that the traffic of this volume of robots can significantly affect the overall efficiency of the site under unfavorable conditions. Of course, although this issue is much less visible for sites that have fewer visits, for highly visited sites that themselves have to handle the traffic of thousands of users on a daily basis, the addition of a lot of traffic from these robots may also be a problem.
In these cases, most webmasters easily use robots.txt to limit the access of search engine robots to different and specified sections that are not very important for SEO and ranking in search engines. In this case, not only the site server will operate with lighter traffic, but also the process of checking and collecting information and then indexing them by robots will be much faster.
Using the robots.txt file can be useful in managing links
Another advantage of using robots.txt is the ability to manage links and page addresses (URL). In the SEO discussion, there is a problem called URL Cloacking. This discussion is actually a kind of SEO technique to hide page addresses from users or search engines. With the help of robots.txt, you can manage this model of links and hide their address.
The most common use of this case is in the use of links related to the discussion of “collaboration system in sales” or “Affiliate Marketing”. In this case, you can manage the links created in the Affiliate system, which are known as Affiliate Links, and hide their addresses so that users are somehow forced to click on them.
Note that this technique should only be performed by professionals. Because URL Cloacking is one of the black hat SEO techniques and if you don’t implement it correctly, you will be accused of violating search engine rules and will be fined by Google.


How the robots.txt file works
The robots.txt file is a text file with a simple structure. The way this file works is determined with the help of default commands and keyword integration. Among the most important and common commands are things like User-agent, Disallow, Allow, Crawl-delay, and Sitemap, and we will describe each of these separately in detail below.
User-agent: This command is used to specify whether bots and buyers can access parts of the site. With this instruction, you can give access to all robots, or by adding a specific robot name, you can give or limit different accesses to only that robot.
Example: A robot enters your site and intends to check and collect information from a specific page, for example, www.example.com/test.html. Before crawling this page, the robot first checks the robots.txt file. For example, the contents of this file are as follows:
User-agent: *
User-agent: * means that all parts of this site are accessible to all bots and crawlers of search engines. But if you intend to specify your information only for a specific bot, you should put the exact name of that bot instead of the star.
Pay attention to the example below. In this example, only the Google robot has the right to access the site pages:
User-agent: Googlebot
Disallow and Allow: With the help of this instruction, it is possible to specify to the User-agent or designated robots which parts of the site to check and index or not. As it is known, the Allow code is used to create access, and the Disallow code is used to limit the access of robots.
Example: If you only include the command “Disallow: /” in the robots.txt file, you are telling the robots that they should not visit, crawl or index any pages of this site. Also, if you want to give full access to all of them, you should use the “Allow: /” command.
You can set specific files, paths, addresses, and pages of your site as selections so that only these parts are accessible or vice versa. Pay attention to the following simple example:
Disallow: /wp-admin/ Allow: /contact/
According to the example above, the entry path to the WordPress admin panel is limited for bots to access, but the Contact page is accessible. In this way, this type of access can be managed very easily and quickly.
How to make a Robots.txt file
Before creating this file, first make sure that such a file has not been created on your site server before. To find out about this, just enter the address of your site and type /robots.txt at the end and hit enter.
That is: www.ded9.com/robots.txt
If you encounter a 404 error when opening this page, it means that such a file has not been created. But if you come across user-agent codes after entering this page, it means that your site has this file. In this case, you should go to the file management section through FTP or the control panel of your site host and find the robots.txt file in the main root of the host. Then you need to run it through an online text editor and edit it. You can also download this file and edit it on your computer and finally replace the saved file with the previous file.
Also, if this file is not found on your site’s host, easily create a txt text file through Windows Notepad and save it with the name robots (in lowercase letters). Then put the commands you need in it and save the file. Finally, upload the prepared file using the same methods mentioned above (via FTP or the host control panel’s file manager) in the main root of the site.
How to Test our robots.txt file and make sure it works correctly?
In normal mode, you can make sure that the commands are correct by opening the address of the robots.txt file and manually checking the commands inside. But a more professional way is to use the robots.txt file testing tool of Google Search Console. More tips:
For this purpose, first, enter the Google Search Console site
Click on the robots.txt Tester section
Select the Test option
If there is no problem in the file, the red Test button will change to the green Allowed button. But if a problem is seen in the file, the problematic line (command) is highlighted and specified.
Also, with the help of this Google tool, you can benefit from other features. For example, you can use the URL Tester section to analyze the address of your website pages to find out which of them are blocked for robots.
Also, this tool is an online editor that you can change its contents with suggested standards. But don’t forget that in order to apply these changes to your site, you need to replace the new edited content with the previous text content in the existing robots.txt on your host.
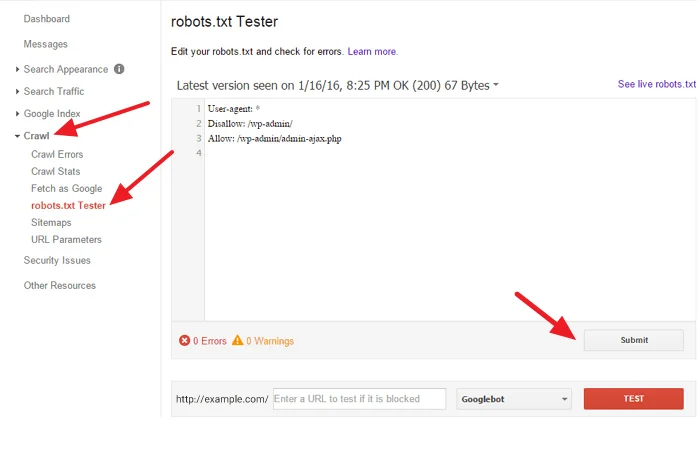

How to find robots.txt Tester in Google Search Console
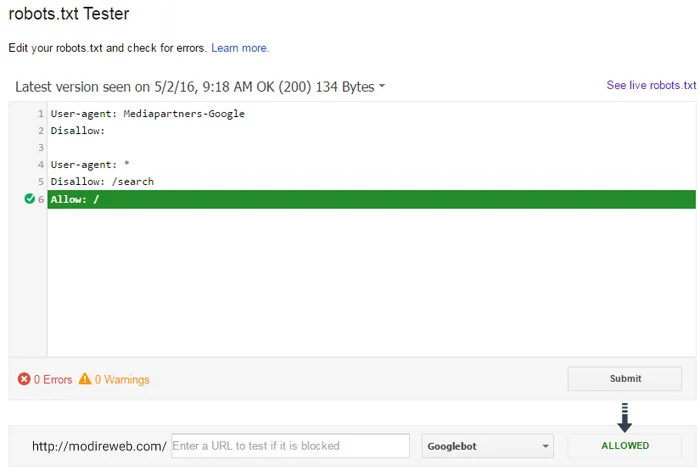

The problem of not having command codes in robots.txt and permission verification. (Allowed)
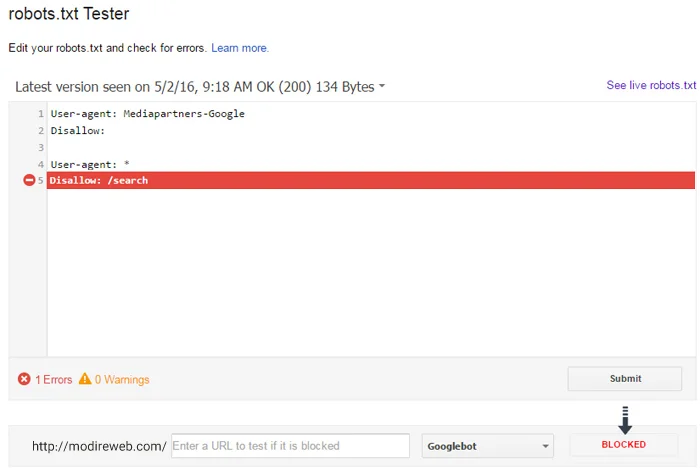
The problem of having command codes in robots.txt and not confirming permission. (Disallowed)

Google has thought of simple measures for this issue. After making changes and editing the text of the robots.txt file with the help of this tool, just continue the said process by confirming (clicking on the Submit button) to be directed to the next section. In the next section, which consists of 3 sections, you can download the new edited robots.txt file. Then you need to replace the new file with the previous file on your host. After this, return to this page again and click the final Submit option to inform Google that the desired file has been updated.
What are the terms of Robots.txt in WordPress?
All the things mentioned above also apply to the WordPress content management system. But there are a few things about WordPress in this field that are worth knowing.
The first point:
In the past, it was suggested to block the WordPress admin panel page or wp-admin through the robots.txt file for robots to access. But after the WordPress update in 2012, this issue no longer mattered. In its new system, WordPress added a default feature to the header tag of the robots.txt file, which included the noindex tag and the command to block access (disallow). So now, without the need for a special case, the management page of your site panel will be automatically removed from the list of search engine indexes.
Second point:
By default, the WordPress content management system has a robots.txt file, which is called a virtual robots.txt file. This means that you cannot directly find and edit this file. The only way to view this file is to open its direct address in browsers (http://www.example.com/robots.txt).
The default instructions in the virtual robots.txt file in WordPress include the following:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
In this case, robots have access to the admin-ajax.php page. If you want to disable this mode without special manipulation, you must go to the WordPress settings on the wp-admin page and enable the Search Engine Visibility option to block all robots from accessing your site.
How to ٍEdit the Robots.txt file
According to what was said (impossibility to directly edit the robots.txt file in WordPress), the only way to edit the robots.txt file is to create a new file from it and upload it to the main root of the site server. In fact, when a new file with this title is created, WordPress automatically disables the robots.txt virtual file.
Important points of the robots.txt file in relation to SEO
As the use of robots.txt instructions is recommended in many cases and will have a good effect for your site’s SEO campaign, overdoing it or making a mistake can also have the opposite result. For this purpose, read the following points carefully and prepare a suitable robots.txt file according to SEO standards:
First of all, check and test your robots.txt file to make sure that an important part of your site is not blocked through it.
Don’t block important CSS and JS files and folders. Don’t forget that Google robots check and index a site from the point of view of a user. As a result, if you block some CSS and JS files and other similar files, your site may not load properly, and this issue can also cause errors and negatively affect the indexing of other pages on your site.
If you are using WordPress, there is no need to block paths like wp-admin and wp-include folders. WordPress does this automatically through meta tags.
Try not to assign too many specific commands to specific bots. It is suggested that if you have a special command, apply it to all robots with the help of the User-agent: * code.
If you want some pages of your site not to be indexed in search engines, we suggest using meta tags in the header of each page. Of course, while the number of these pages is small or this process is not difficult for you.
Conclusion
The robots.txt issue is not something you want to spend a lot of time on or constantly trial and error. If you need to take advantage of this feature, the best thing to do is to use the Google Search Console online tool. With the help of this tool, you can manage, edit, debug and update your robots.txt file much more easily.
It is also suggested to avoid updating this file as much as possible. The best thing to do is to prepare a complete and final robots.txt file right after building the website. Although the continuous updates of this file will not affect your site’s performance, it can complicate the process of crawlers and robots accessing your site.
FAQ
What is a robots.txt file in SEO?
A robots.txt file tells search engine crawlers which pages or sections of your site they can or cannot access.
How does robots.txt affect search engine indexing?
By blocking crawler access to unnecessary or duplicate pages, robots.txt helps focus indexing on your most important content.
Can robots.txt improve SEO?
Yes — when used correctly, it prevents crawl waste and supports better indexing and resource allocation by search engines.