One Of The Practical Methods In Machine Learning Is Group Classification Or Ensemble, In This Article, We Intend To Provide General Information About This Method And Its Types.
One of the practical methods in machine learning is group classification or ensemble, in this article we intend to provide general information about this method and its types.

What is an ensemble?
In machine learning, the Ensemble method or the collective classification of several so-called weak learning algorithms (weak Learner, which are basic models that create a complex model by combining several weak models. Weak models should be only slightly better than the random mode).
To be able to achieve better performance than individual algorithms and to provide a more accurate and accurate forecast in practice. An ensemble is a machine learning method with an observer who first learns and then, with what he has learned, makes his predictions on unknown data.
To put it simply, suppose you want to move a heavy object, but you can not do it alone. In this situation, with the help of, for example, 3 other people (each of whom alone is not able to move the body), you can do this and move the body. In fact, with the help of collective power, you gained the ability to do something.
Ensemble types
There are two popular ways to create Ensemble classification algorithms, which are Bagging and Boosting. In the following, we will explain each of these two methods.
1- Bagging method
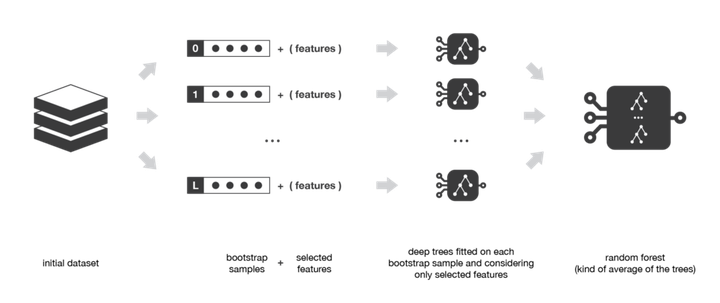
This method is practically one of the Ensemble models that aim to reduce the variance in the decision tree classifier. In this method, we actually create several instances of data using the Bootstrapping trick (the size of the data does not change but the data is moved randomly). We then use each of the new datasets to teach a decision tree.
Finally, we will have the result of each of the created models and we will predict the result of the test data using voting (so-called using majority vote).
Among the advantages of bagging, a method is the reduction of the problem of over-fitting (a model that learns noise over-fit instead of signals), the possibility of excellent management of multidimensional data, and high accuracy even in missing data.
Of course, keep in mind that this method also has a problem, and that is that since in the Bagging method we actually declare the average as a result, we will not have an exact value for the classification and regression models.
Random Forrest is one example of a Bagging Ensemble.

2- Boosting method
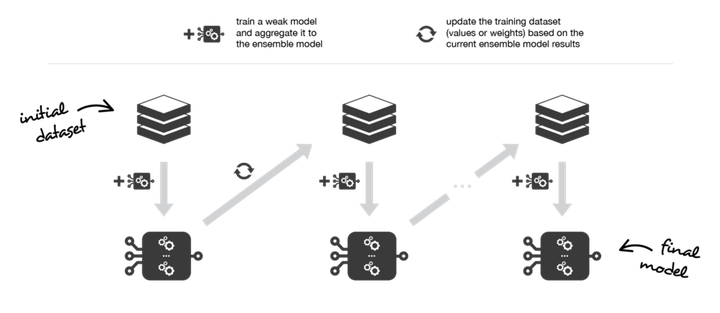
Another method in the Ensemble classification is the Boosting method. In this method, again, the combination of several weak learners is used to create a strong model, but none of the learning models are separate, but we are facing an iterative method that each step depends on the previous step.
In this method, the focus is on the most difficult examples ever seen. For example, suppose you have several examples of exam questions. Each time you read a series of sample questions, mark the most difficult questions and then return to them.
In the Boosting model, each time, the incorrectly classified samples become more valuable, so that little by little, the focus is on them, and finally a strong model is created.
Of course, it should be noted that Boosting is used just like the Bagging method for classification and regression issues.
Boosting algorithms include AdaBoost, Gradient Tree Boosting, and XGBoost.