

Data Structures Is One Of The Most Important Computer Courses That Has Many Hidden Points. This Course Is Considered As A Course With High Coefficients In The Entrance Exam For Master’s Degree In Computer, Doctorate, Artificial Intelligence, And Software.
Types Of Trees: At the undergraduate level, the topics described in this course are repeated in various ways in other classes.
When you graduate from university and work for a software company, you must use the data structure to do most projects. Therefore, you should not ignore any of the data structure issues and ignore them.
What should professionals be familiar with the principles of data structure?
In general, familiarity with data structure is essential for data scientists, data engineers, data mining professionals, machine learning professionals, and programmers. For nearly half a century, software engineers have interacted with data structures in a variety of ways. So in topics like data mining, machine learning, and programming, you need to have a thorough understanding of data structure.
What is data organization? Organizing data means using a specific method based on a logical or mathematical model used to optimize data. There are different types of data structures, each of which is used for a particular application.
An important point to note is the difference between the data structure and the algorithm. Data structure refers to storing data on a computer for more accessible and more efficient access, while an algorithm is a way to solve a problem by a computer.
Which of the following is a valuable data structure?
There is no clear answer to this question because each data structure issue solves a specific problem. However, some data structures are more widely used in programming projects, the most important of which are Array, Stacks, Queue, Linked List, Tree, Graph. ), The prefix tree (Trie) and the hash table (Hash Table). Among these, trees have a special place that is the subject of this article.
What is a tree?
A tree is a hierarchical data structure that consists of vertices (nodes) and edges that connect them. Trees have a function similar to graphs, except that trees, unlike charts, do not have a cycle. Trees are widely used in artificial intelligence and intelligent algorithms and use intelligent solutions to store data and solve problems effectively.
For example, all the chess games you play are tree-based. It has several trees, including the N-ary tree, the Balanced Tree, the Binary Tree, the Binary Search Tree, and the Oval Tree (AVL Tree).
He mentioned the Red-Black Tree and the 2-3 tree. Many cyberspace users do not know about using the tree in one of the most sophisticated and creative technologies we hear about these days. Trees play a crucial role in blockchain technology. Not harmful to know, the first attempt to build an encrypted blockchain was made in 1991 by Stuart Haber and Scott Storrenta, cryptographers.
They managed to collect several documents in one block based on the hash tree and then created a self-managed blockchain database using a peer-to-peer network and a distributed scheduling server.
This technology evolved gradually to see that many digital cryptocurrencies have been created based on this technology. Given the importance of trees in the digital world, we introduced this article’s most widely used trees.
Tree 2-3
Tree 2-3 is a kind of self-balancing search tree. Binary search trees may lose their balance with varying degrees and deletions. Consider a case where you are searching for a binary tree, and you enter n data that are randomly sorted from small to large, respectively.
In this case, the tree becomes a linked list in which the search is of order (O (n), and in addition to losing the advantage of using the binary search tree, a large amount of memory is allocated to empty pointers. Implementing insert and delete functions of trees 2-3 is such that the tree remains balanced during degrees and deletions.
Tree 2-3 has three leaf node nodes with only one value, node two, and node 3. In node 2, X is the node’s value, L is the left subtree, and R is the right.
Each node two must have the following properties:
- Any value in L must be less than X.
- Any value in R must be greater than X.
- The path lengths from the roots to the leaves of each subtree should be the same.
In node 3, X is the node’s value, L is the left subtree, M is the middle, and R is the right. Each node three must have the following properties:
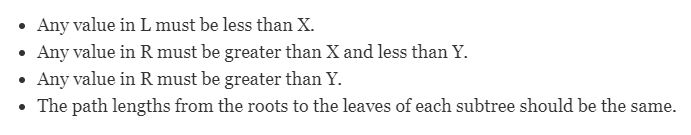

It should note that all values are present in the leaf nodes, and the internal nodes are created only to guide the search. Each internal node is a node 3 (with two or three children) whose X value is equal to the smallest value in the second subtree, and its Y value (if any) is similar to the smallest value in the third subtree.

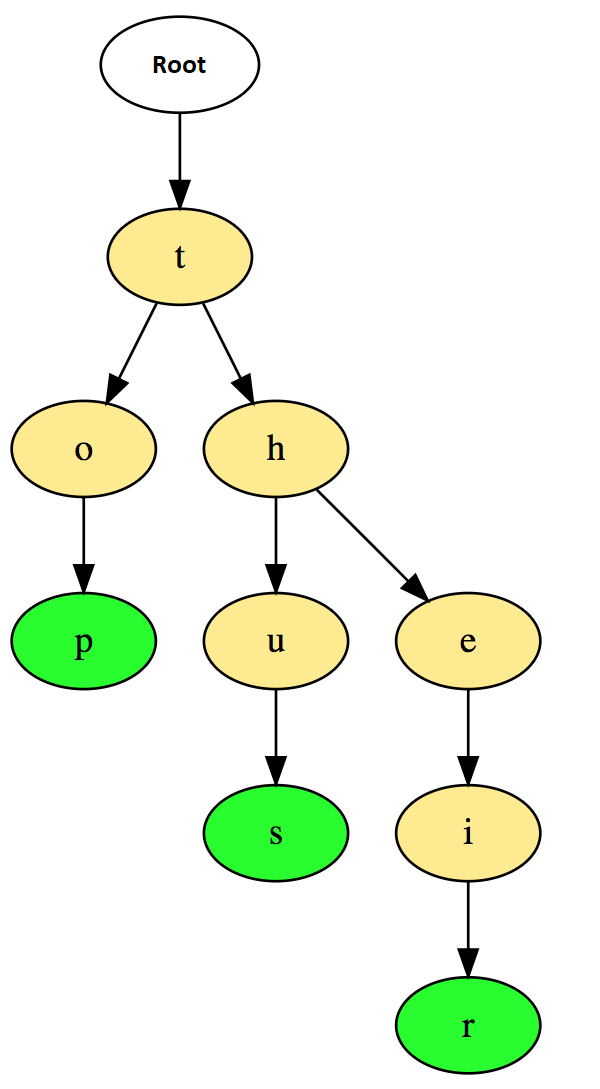
figure 1
Prefix tree
The Trie, called the Prefix Tree, is used for issues related to strings. Prefix trees allow quick retrieval and are mainly used to search for words in dictionaries, auto-suggest in search engines, and even IP routing. Figure 1 shows the function of this tree. As you can see, the terms are stored up and down in this tree.
In the figure above, the green nodes p, s, and r represent the ending letters in words top, thus, and their. Important points to note about prefix trees are how to calculate the total number of words in the prefix tree, display all the words stored in the prefix tree, sort the elements of an array using the prefix tree, format the words in a dictionary, and Build the T9 dictionary.
Extension tree
A Trie extension tree contains extensions of a given string as a key and their location in the series as a value. The suffix tree for an S string is a tree whose edges are labeled with lines so that each suffix S corresponds to a path from the root of the tree to a leaf, so this tree is a base tree for S suffixes. Building such a tree for an S string requires linear time and space in terms of S length.
Once this tree is created, string operations, such as finding a subdirectory in S, finding a subdirectory with an allowable number specified for errors, finding matches for a regular expression pattern, and so on, can be done quickly.
Binary search tree
A binary search tree, sometimes called a regular binary tree, is a data structure and is a type of binary tree. A binary tree is a data structure for storing data such as numbers. Binary Search Tree allows you to search for a number and add and remove that number faster.
In addition, it allows the implementation of dynamic collections and searches tables. The order of the nodes in the binary search tree is such that the remaining half of the tree is not examined in every comparison. Therefore, the tree search time is proportional to the logarithm of the number of numbers stored in the tree. This time is much less than the linear search time in an unordered array, but it is slower than the hash operation.
Typically, a binary search tree consists of several nodes, each of which has a key. The keys are unique, and there is no duplicate key in the tree.
All the keys in the left subtree are smaller than the root node key.
All keys located in the right subtree are more significant than the root node key.
The right subtree and the left subtree are binary search trees.
Self-balancing binary search tree
A self-balancing binary search tree can be any node-centric binary search tree that automatically keeps its height (maximum number of steps below the root) small in inserting and deleting the desired element.
These structures generate efficient executables for immutable lists and can be used as abstract data types such as associative arrays, priority queues, and collections. Self-balancing binary search trees can typically be used to build and maintain indexed directories.

The triple search tree
The triple search tree is a type of prefix tree, except that the nodes are in the same state as the binary search tree but have three children. Like all prefix trees, a triple search tree can be used as associative array structure data with string search capabilities. Typical uses of the triple search tree include debugging and auto-complete.
Like a binary tree where each node has a value and two pointers to its subtrees, each node of a triple search tree contains one character and three-pointers under the first, second, and third subtrees, with the letters more minor, equal child, and child. They are known to be older.
A node can point to its parent node or an index to indicate whether we have reached the end of the word. The pointer to the younger child refers to a node with a minor character than the parent.
Binary tree
A binary tree is a tree data structure in which each node has a maximum of two child nodes called the right and left children. In a binary tree, the maximum degree of each node can be two. Binary trees are used to implement binary and mass binary search trees and for efficient search and sorting. A binary tree is a particular case of a k tree, in which k equals 2.
Optimal binary tree
The optimal search binary tree is a type of binary search tree. If we know in advance what elements are to be inserted in the tree and see the probability that each of these elements will search, we can create a more optimal form of the binary search tree. There are two ways to optimize a binary search tree. One is to create a balanced search binary tree, and the other is to create an optimal search binary tree by calculating the probability of access to each element.
If the data is already ready, we can search it in a binary tree to create a balanced tree. In such cases, having a balanced search binary tree, in the worst case, the time cost is equal to (O (log n).
Cotton binary tree
In a binary tree, the number of empty connections is greater than the number of non-terminal connections. In a binary tree of the natural relationships, i.e., 2n, the number of n + 1 references is empty. These empty connections can use to communicate with other tree nodes. The tree whose meaningless relationships are suspected in this way is called the threaded binary tree. A binary tree can be strung in several ways.
This stringing depends on the tree scrolling method. The threaded binary tree allows the values in the binary tree to be scrolled through the linear scrolling method faster than the reverse scrolling of the tree as an intermediate.
In addition, it is possible to find the parent of a node in a binary tree without the use of parent pointers or the use of stacks, although this is a bit slow. This feature is useful when the stack space is small or when the accumulation of parent pointers is inaccessible.
Black Red Tree
The red-black block tree is a type of self-balancing binary search tree. The black rose tree was first called the symmetric B binary tree by Rudolf Bayer in the 1970s but later became known as the black rose tree.
Compared to the trees we mentioned, the black-red tree has a complex structure, yet in the worst case, it is speedy. To be more precise, the search, delete and insert time for this tree is like O (log (n), where n is the number of nodes.
The main advantage of this data structure over the AVL tree is that insertion and deletion operations are performed by scrolling the tree from top to bottom only once and changing the color of the nodes, making it easier to implement than the AVL tree.
A tree in which each node is painted in one of two colors, black or red, the root is always black. The leaves are black (the leaf is a knot that has no children, it is an empty knot). It is called a black, red tree.
Who is the tree?
The KD tree organizes points in k-dimensional space and is more of a generalization of the binary search tree. This tree is a functional data structure for applications such as searches that contain multidimensional search keywords.
Each node is the next K-spot in this data structure, and each non-leaf node can be described as a separating generator that divides space into two parts.