


Database Sharding Nedir, Avantajları ve Dezavantajları Nelerdir?
Uygulamaların veya Web Sitelerinin Tasarımı, Kullanıcı İsteklerine ve Gelen Trafiğe Düzgün Yanıt Verebilmeleri İçin Zamanla Ölçeklenebilme Yeteneğine Sahip Olmalıdır.
Ölçeklenebilirlik, veri odaklı uygulamalar ve web siteleri bağlamında önemlidir ve veri güvenliği ve bütünlüğünü sağlayacak şekilde yapılmalıdır.
Bir web sitesinin veya uygulamanın ne kadar popüler olacağını ve ne kadar süre ünlü olacağını tahmin etmek zor olabilir. Bu nedenle bazı kuruluşlar, veritabanlarını dinamik olarak ölçeklendirmelerine olanak tanıyan bir veritabanı mimarisi seçer.
Bu yazımızda temel veritabanı mimarilerinden birini inceleyeceğiz. Bu değerli ve gerekli mimariye Database Sharding denir.
Parçalama nedir?
Parçalama, sorguları kolayca yönetmek için verilerin birden çok tabloya ve veritabanına bölündüğü bir veritabanı tasarım modelidir. Günümüzde önemli veri tabanları bu tekniği çeşitli şekillerde desteklemektedir. Örneğin, Oracle’ın veritabanı yönetim sisteminde, Oracle Sharding, bir veri kümesinin parçalarını farklı bilgisayarlarda veya bulutta barındırılan veritabanları (parçalar) arasında dağıtır.
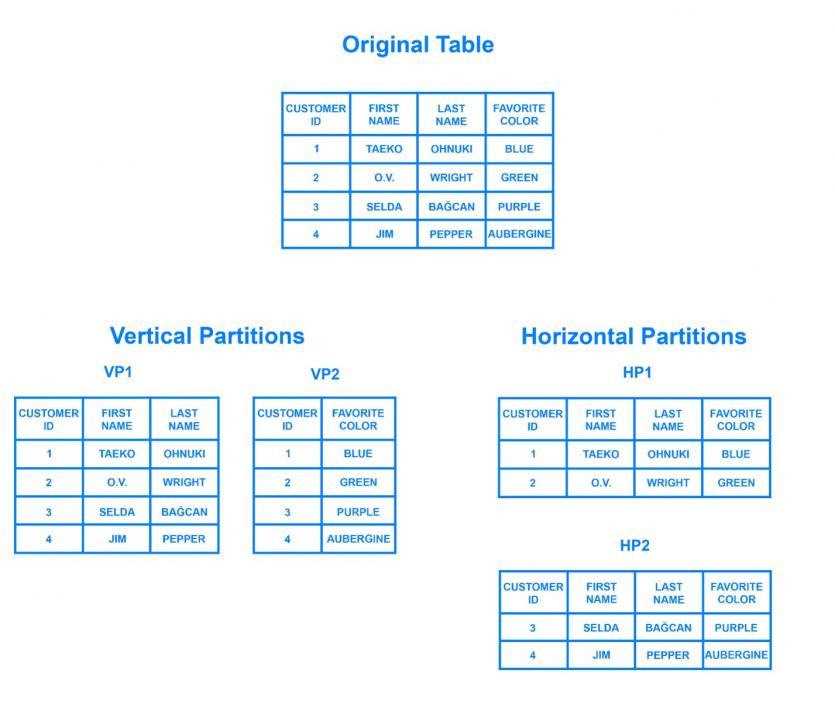
Burada “yatay” ve “dikey” olmak üzere iki kelimeyi içeren bölme adı verilen önemli bir kavram vardır.
Yatay bölümlemede, saklanan kayıtlar iTable tablosuna burada bölüm olarak bilinen bir grup olarak girilir. Bu durumda, tablolar aynı şemaya ve sütunlara sahiptir, ancak içlerinde depolanan veriler farklı ve benzersizdir; Başka bir deyişle, hiçbir tablo aynı verileri içermez.
Parçalama, bölümleme işlemini yatay olarak gerçekleştiren bir veritabanı mimarisi kalıbıdır. Bir tablonun satırlarını birkaç farklı tabloya ayırma işlemi, bölümleme olarak bilinir. Her bölüm aynı düzene ve sütunlara sahiptir, ancak tamamen farklı satırlara sahiptir. Aynı şekilde her bölümde depolanan veriler benzersizdir ve diğer hücrelerde depolanan verilerden bağımsızdır.
Dikkat edilmesi gereken önemli bir nokta, yatay bölümleme ile dikey bölümleme arasında iletişim kurmaktır. Dikey bölmede depolanan veriler, farklı hücrelerdeki verilerden bağımsızdır ve her birinin farklı satırları ve sütunları vardır. Dikey olarak bölümlenmiş bir tabloda, sütunlar birbirinden ayrılır ve yeni, ayrı tablolara yerleştirilir. Şekil 1, bir tablonun yatay ve dikey olarak nasıl bölümlenebileceğini göstermektedir.
Yatay ve dikey bölümleme arasındaki farklar
Dikey bölümlemede, tablolarda benzersiz sütunlar oluşturulur. Bu tablolarda depolanan veriler de şaşırtıcıdır; Başka bir deyişle, iki tablo (bölüm) aynı yapıyı ve verileri içeremez.
Şimdi soruya geliyoruz, yatay ve dikey bölümleme arasındaki farklar nelerdir? Yatay bölümlemede sadece tabloların verileri benzersizdir. Buna karşılık dikey bölümlemede, verilere ek olarak tablonun sütunları da farklıdır.
Şekil 1’de Orijinal Tablomuz var; yatay olarak tasindigimizda, HP1 ve HP2 adli, ayni sema veya veritabani yapisina sahip ancak farkli veriler içeren iki tablomuz olacak.
Ancak bu tabloyu dikey olarak bölümlendirdiğimizde wTablee şeması farklı olan VP1 ve VP2 isimli iki tablo karşımıza çıkıyor. Ek olarak, her biri belirli verileri depolamaktan sorumludur.
Bu açıklamalarla parçalama, verilerin her biri belirli bir tabloda depolanan küçük birimlere bölünmesini ifade eder. Bu durumda, her bir tabloyu ve verileri çamaşır suyunun yanına yerleştirerek eksiksiz bir veritabanına sahip olacağız.

Sharding mimarisi ne gibi avantajlar sunuyor?
Dikey ölçeklendirme süreci (Vertical Scaling), BT ekiplerinin, veritabanlarının ve web sitelerinin performansının düşmemesi için kullanıcı sorgularına daha iyi yanıt vermek için sunucuların merkezi işlemcisi veya ana belleği gibi işleme kaynaklarını yükseltmesine olanak tanır. Sharding, yatay ölçekleme modeline dayalı tasarım sürecini yürütebilmeleri için veritabanı tasarımı alanındaki geliştiricilerin elini açar. Bu durumda, işlem verilerini ve sorguları artırmak ve farklı veritabanlarını en uygun şekilde kullanmak için sunuculardaki yükü dağıtmak mümkündür.
Dikey genişleme söz konusu olduğunda, iş faaliyetleri genişledikçe ve kullanıcı sayısı arttıkça sunucunun isteklere cevap vermesi için donanım altyapısı yükseltilebilir. Ancak, uzun vadede kuruluşa çok pahalıya mal olacağından, donanım ölçeklenebilirliğinin yalnızca bir noktaya kadar mümkün olduğunu unutmayın.
Bir veritabanına standart bir sorgu gönderdiğimizde, belirli bir tabloda milyonlarca kayıt varsa, indeksleme doğru yapılsa bile yanıt süresi hızlı olmayacaktır. Parçalama mimarisine dayalı iken, girilen sorgunun daha az kayıt arasında aranabilmesi için bir tablo birkaç ayrı tabloya bölünür.
Bu durumda, veri erişim hızı önemli ölçüde artar.
Standart bir veritabanına (Unsharded Database) dayalı web tabanlı bir uygulama. En sık kullanılan veriler önbelleğe alınır ve uygulama bu bilgileri kullanabilir. Ayrıca sharding, veritabanı kullanılamaz hale geldiğinde veya bir sunucu sorunu oluştuğunda, uygulamanın belirli bir süre boyunca kararlı performansını sürdürmesini sağlar.
Veritabanı sunucusunda bir sorunla karşılaşırsa performansı bozulur. Neredeyse çok sayıda İran web sitesi böyle bir sorunla karşı karşıya. Bu arada, Sharded Database mimarisine dayalı web tabanlı bir uygulamada böyle bir sorun meydana gelirse, yalnızca bir shard (veritabanındaki bir tablo) kesintiye uğrar ve uygulama kararlılığını koruyabilir. Bu durumda programın sadece bölümleri geçici olarak kullanıcılara hizmet veremeyecektir.
Sharding mimarisinin dezavantajları nelerdir?
Hiper mimari, web tabanlı uygulamalar için daha iyi kararlılık ve performans sunar, ancak dezavantajları da vardır. Yukarıdaki mimarinin önemli dezavantajlarından biri, veritabanlarının aşırı karmaşıklığıdır. Yani sharding döngüsü doğru yapılmadığı takdirde veriler birbiriyle karışabilir, tablolardaki yazma işlemleri doğru yapılmaz veya tabloların bütünlüğü bozulur.
Parçalama mimarisinin diğer bir sorunu, farklı bölümler arasındaki dengesizliktir. Bu konuyu daha iyi anlamak için, adları a’dan s’ye kadar olan harflerle başlayan kullanıcıların adlarını ve o’dan z’ye kadar olan kullanıcıların verilerini sakladığımız iki tablomuz olduğunu varsayalım. Tipik olarak, adı B harfi ile başlayan kullanıcı sayısı, alfabenin diğer harflerine göre daha fazla olabilir. Böyle bir durumda a’dan s’ye kadar olan harflerin saklanması açısından saygın olan tablo çok büyük hale gelir ve bu da büyük hacimli kayıtlardan veri alma hızının artmasına neden olur.
Yukarıdaki mimarinin bir başka dezavantajı da, bir veritabanını bölümlendirdiğimizde, önceki yedeklemelerin artık bu noktadan itibaren yardımcı olmamasıdır. Böyle bir durumda ve gerekirse, yedek kopyalar da bölümlenmiş bir biçimde hazırlanmalıdır ki bu maliyetlidir ve hata olasılığı yüksektir.
Parçalama mimarisi nasıl çalışır?
Veritabanımızı iş gereksinimlerine göre bölümlere ayırmamız gerektiğini varsayalım; başlamak için ne yapmalıyız? Yukarıdaki mimariyi daha iyi anlamak için, verileri diğer bölümler arasında dağıtmak için yukarıdaki mimariyi uygulamanın farklı yöntemlerini tanımamız gerekir. Genel bir kural olarak, diğer birkaç veritabanını veya tabloyu sorguladığınızda, sorgunun tam olarak hangi bölüme veya tabloya gönderileceğini bilmeniz gerektiğini unutmamalısınız; aksi takdirde yanlış sonuçlarla ve bazen veri kaybıyla karşı karşıya kalırsınız.
Anahtar Tabanlı Parçalama: Yukarıdaki mimaride, veritabanına yeni veriler depolandığında, o verilerle ilişkili bir anahtar dikkate alınır. Örneğin, bir çevrimiçi mağazaya yeni bir müşteri kaydolursa, müşteri_kimliği anahtardır. Bu anahtar daha sonra aldığı girdiye göre verilerin hangi partition’da saklanması gerektiğini belirleyen bir fonksiyona geçirilir. Verilerin doğru hücrelerde saklandığından emin olmak için böyle bir fonksiyona giren değerlerin girilmesi gerekir. benzersiz bir doğaya sahip olmak için Hash Fonksiyonu olarak bilinmelidir. Bu konuyu daha iyi anlamak için Birincil Anahtar, yukarıdaki mimaride Parça Anahtarı olarak bilinen bu tür veriler olarak kabul edilebilir.
Anahtar Tabanlı Parçalama mimarisiyle çalışmanın zorluklarından biri, yeni sunucular eklersek veya mevcut sunucuların sayısını azaltırsak sorunlarla karşılaşabilmemizdir.
Bu şekilde, bir kümeye yeni bir sunucu eklediğimizde, her sunucu yeni verileri kaydetmek için bir karma değer gerektirir. Bu durumda veriyi mevcut sunucuya aktarmayı düşünüyorsak, veriyle ilişkili hash değerini güncellememiz gerekiyor ki bu da maliyetli bir durum.
Aralık Tabanlı Parçalama: Aralık tabanlı bölümleme, verilerin belirtilen değerlere göre paylaşılmasını içerir. Yukarıdaki modeli daha iyi anlamak için, tüm ürünlerle ilgili verilerin depolandığı bir çevrimiçi mağazada bir veritabanınız olduğunu varsayalım. Bu veri tabanını bölümlemek için ürün fiyatlarına göre farklı veritabanları veya tablolar kullanılabilir. Bu mimariyi uygulamanın avantajlarından biri, tüm bölümlerin şemasının aynı olması için kullanım kolaylığıdır. Böyle bir durumda, yeni verilerin hangi bölümde saklanacağını belirlemek için uygulama düzeyinde bir değişiklik yapmayı düşündüğümüzde, fiyat aralığına bakmamız ve buna göre uygun bölümü seçmemiz gerekir. Seç
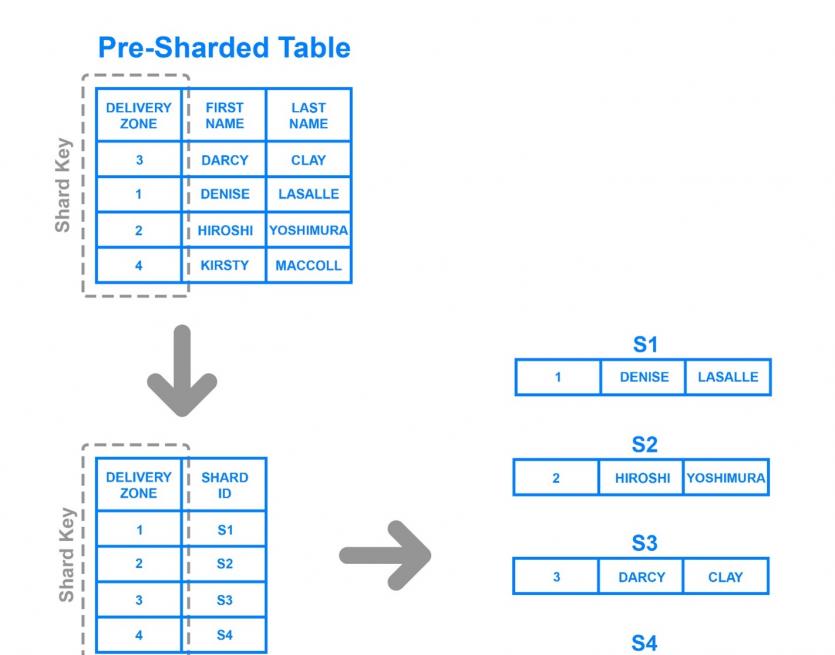
Directory-Based Sharding: Şekil 2’de gördüğünüz gibi bu mimaride Lookup Table adlı bir bileşene ihtiyacımız var. Bu bileşen, hangi bölümün hangi tür verileri tutması gerektiğinin belirlenebilmesi için Parça Anahtarını depolamaktan sorumludur. Yani bu tablo, kitapların sonunda hangi terimin hangi bölümde veya hangi sayfada kullanıldığını belirten bir lisTablewords gibidir.
Şekil 2’de gösterildiği gibi, Teslimat Bölgesi sütunu bir Parça Anahtarı olarak kabul edilir. Ardından, veriler bu sütuna göre Arama Tablosuna kaydedilir. Bu durumda, her anahtarın hangi bölümle ilişkilendirildiği açıktır. Önceki mimariye (Range-Based Sharding) kıyasla, veri depolama için hangi bölümün kullanılması gerektiği önemli olmadığında, Directory-Based Sharding önceki örneğe göre daha iyi performans gösterir.
Yukarıdaki mimarinin avantajlarından biri sunduğu inanılmaz esnekliktir. Bu durumda geliştiriciler, verileri farklı bölümler arasında dağıtmak için özel algoritmalarını kullanabilirler. Ek olarak, dinamik olarak yeni bölümler eklemek kolay olacaktır. Yukarıdaki mimarinin tek dezavantajı, sorgunun başlangıç noktası olan Arama Tablosu herhangi bir nedenle bir sorunla karşılaşırsa programın tamamının veya en azından birçok bölümünün performansının başarısız olması.

son söz
Bazı programcılar ve veritabanı uzmanları, veritabanlarının hantal hale gelmesine neden olan sürekli artan bilgi miktarının, parçalama mimarisine geçiş gerekliliğini ikiye katladığına inanıyor. İşletmeler tarafından günlük olarak üretilen veri hacmi çok büyük olduğundan, bunları tek bir veritabanı tek başına yönetemez veya veritabanında veri okumanın/yazmanın önemi, bir sunucunun kaynakları buna yanıt vermeyecek kadar önemlidir; Bu nedenle, yazılım ekipleri parçalama kullanmak zorunda kalır.
Veritabanına uygulanan bölümlerin eklenip kaldırılabileceğine ve verilerin herhangi bir hasar veya kayıp olmadan iki kez bölümlenebileceğine dikkat edilmelidir. Günümüzde Oracle veya Microsoft SQL Server gibi modern veritabanları, bir veri setinin parçalarını farklı bilgisayarlarda veya bulutta bulunan veritabanlarına (shards) dağıtır, böylece bir bölümle ilgili bir sorun olması durumunda veritabanına erişim tamamen kesintiye uğramaz.
Şimdi bu kritik soruya geliyoruz: shard kullanmalı mıyız?
Bölümlenmiş bir mimariye dayalı bir veritabanını uygulayıp uygulamamamız, masaüstü ve web tabanlı uygulama geliştirme dünyasındaki en sıcak konulardan biridir. Bu mimarinin tasarıma eklediği operasyonel karmaşıklık nedeniyle bazıları parçalamayı yalnızca bir işletmenin veritabanının büyüyeceğinden ve ölçeklenebilirliğinin kaçınılmaz olduğundan emin olduklarında kullanır.
Bu nedenle, yukarıdaki mimarinin yalnızca bir veritabanının bölümlenmesinin gerekli olduğu durumlarda kullanılması gerektiğini önermektedir. Genel olarak, geliştirmeyi planladığınız yazılım projelerinde aşağıdaki senaryolarla karşılaşırsanız parçalama kullanılmalıdır:
Uygulama verilerinin miktarı, tek bir veritabanı düğümünün depolama kapasitesini aşıyor.
Veritabanındaki yazma/okuma işlemlerinin hacmi, tek bir düğümün kaldırabileceği hacmi aşarak yanıt sürelerinin veya işlem taahhütlerinin uzamasına neden olur. Bu durumda, bilgiye erişimdeki gecikmenin mümkün olduğunca düşük olması için parçalama kullanılmalıdır.
Ağ bant genişliği, tek bir veritabanı düğümü ve uygulamasının gerektirdiği bant genişliğinden daha azdır, bu da yanıt sürelerinin uzamasına veya kesintilere neden olur.